|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Глава 7 Статистика Все психологические исследования включают статистическую обработку данных. Нельзя стать исследователем в области психологии, не обладая знаниями основ статистического анализа. Кроме того, не имея элементарных представлений о том, что лежит в основе разных статистических показателей, невозможно понять и оценить исследования других людей. Сказанное выше хорошо известно всем студентам, достаточно далеко продвинувшимся в изучении психологической науки. Все они также знают, что овладение статистикой — долгий процесс, который требует прослушивания нескольких курсов и прочтения нескольких увесистых учебников. Я не буду пытаться ужать содержание нескольких книг до одной главы. Моя задача намного скромнее: изложить в качестве дополнения к материалам о тестах некоторые основы и принципы, стоящие за статистическими процедурами. Эта глава может быть введением или дополнением к курсу статистики, а также может служить материалом, помогающим освежить уже имеющиеся знания. Изложение в этой главе идет в направлении от сравнительно простого к более сложному. Начнем с того, что вспомним цели использования статистических показателей, затем, в качестве примера статистического объяснения, приведем уже знакомый вам t-критерий. Остальная часть главы в значительной мере будет посвящена усложненным вариантам простого анализа с использованием t-крите-рия — разнообразным ситуациям, когда нужны другие статистические показатели, их типам, а также основаниям для выбора между этими показателями. Поскольку каждый случай рассматривается кратко и в общих чертах, для каждой из затронутых тем предлагается список литературы. Использование статистических показателей Используя статистические показатели, психологи преследуют две цели: описать данные и прийти к логическому заключению об их значении. Первая из этих целей проста и понятна, достижение второй цели связано с определенными трудностями. Таблица 7.1 Количество агрессивных действий в выборке детей дошкольного возраста (гипотетические данные)
Дескриптивные статистические показатели Вернемся к одному из предыдущих примеров: исследованию агрессии методом наблюдения в условиях детского сада. Допустим, исследователь собрал данные, представленные в табл. 7.1. Как можно заметить, имеют место значительные индивидуальные различия в частоте агрессивных действий; вполне вероятно, что есть также различия между полами и возрастными группами. Но как разобраться в этом хаосе цифр и определить истинное положение вещей? Первый шаг — охарактеризовать данные при помощи ряда дескриптивных статистических показателей. Большинство дескриптивных статистических показателей используется для выявления центральной тенденции, или преобладающей формы ответов в выборке. Чаще всего в качестве меры центральной тенденции выступает среднее арифметическое, или просто среднее. Из табл. 7.2 явствует, что группы испытуемых из нашего гипотетического исследования действительно имеют разный средний уровень агрессии. Чаще всего среднее — наиболее информативный дескриптивный статистический показатель. Однако он не единственный, в ряде случаев знание лишь среднего не дает полного представления о полученных результатах. Сравним группы 3- и 4-летних мальчиков. Как явствует из табл. 7.2, средний уровень агрессии у старших мальчиков выше. Однако сырые данные из табл. 7.1 свидетельствуют о том, что фактически большинство показателей агрессии обеих групп достаточно близки. Более высокое среднее у старших детей явилось следствием наличия нескольких очень высоких показателей. Или же сравним группы 3-летних мальчиков и девочек. Полагаясь на средние значения из табл. 7.2, мы могли бы заключить, что эти группы имеют одинако- вый уровень агрессии. Однако сырые данные из табл. 7.1 свидетельствуют о том, что эти средние значения имеют разные основания. Приведенные выше примеры демонстрируют необходимость иных дескриптивных статистических показателей помимо среднего арифметического. Есть еще две меры центральной тенденции. Одна из них — медиана. Медиана — это центр распределения, выше которого находится одна половина показателей, а ниже — другая. Сравним вновь результаты 3- и 4-летних детей. Из табл. 7.2 явствует, что данные результаты имеют общую медиану — 4. Это свидетельствует о фундаментальном сходстве двух распределений, сходстве, которое мешает заметить разница средних. В целом, медиана приобретает особце значение тогда, когда распределение асимметрично, то есть включает несколько необычно высоких или низких показателей. В таких случаях среднее может дать искаженную картину типичных ответов. Таблица 7.2 Дескриптивные статистические показатели для данных из таблицы 7.1
Третья мера центральной тенденции — мода. Мода — показатель, наиболее часто встречающийся в определенной группе. Эта мера используется редко, однако в некоторых обстоятельствах ее значение довольно информативно. Рассмотрим, к примеру, данные 3-летних девочек из табл. 7.1. Ранее мы отметили, что средний уровень агрессивных действий в этой группе — 5,0 — практически такой же, как и у мальчиков. Однако, в отличие от мальчиков, для 3-летних девочек модальным было нулевое значение. Этот факт вполне заслуживает того, чтобы упомянуть о нем в отчете. Наряду с центральной тенденцией, дескриптивные статистические показатели характеризуют изменчивость распределения. Нам необходимо знать не только, какова центральная тенденция, но и то, насколько приближаются показатели к центральному значению или отклоняются от него. Чаще всего мерой изменчивости служит дисперсия. При ее расчете сначала находят среднее для выборки. Затем определяется разница между этим средним арифметическим и показателем каждого из испытуемых. Эти значения разности, или «отклонения», возводятся в квадрат, суммируются, а полученная сумма делится на N - 1, результатом чего и является показатель дисперсии. Таким образом, дисперсия — это приблизительно среднее квадратичных отклонений; «приблизительно», поскольку делитель равен N - 1, а не N. Чем больше разница между индивидуальными показателями, тем больше дисперсия. В научных статьях в качестве меры изменчивости обычно указывается не дисперсия, а стандартное отклонение. Стандартное отклонение — это просто квадратный корень из показателя дисперсии. В табл. 7.2 он подсчитан для каждой из групп нашего гипотетического исследования. Полученныезначеиия стандартного отклонения подтверждают наши интуитивные предположения о степени разброса индивидуальных показателей в группах. Обратите особое внимание на весьма значительное стандартное отклонение у 4-летних мальчиков, в группе, где было отмечено несколько крайне высоких показателей. Статистические показатели, выводимые логическим путем Предположим, мы получили значения среднего арифметического, представленные в табл. 7.2. Оказывается, что уровень агрессии изменяется как функция от возраста и пола. Но как выяснить наверняка, является ли обнаруженное различие истинным или это просто случайные колебания? На этот вопрос призваны ответить статистические показатели, выводимые логическим путем. Для объяснения смысла статистических показателей, выводимых логическим путем, нужно вспомнить некоторые разграничения (имеющие частичное совпадение), введенные в предыдущих главах. Одно из них — разграничение между истинными показателями и погрешностями измерения. Любой показатель состоит из двух компонентов; действительного результата испытуемого, полученного при измерении, и любого рода погрешности измерения, возникающей при попытке выявить этот истинный показатель. Второе разграничение — между первичной дисперсией и вторичной дисперсией, или дисперсией ошибки. Первичная дисперсия связана с изучаемыми независимыми переменными; вторичная дисперсия, или дисперсия ошибки, обусловлена действием всех других факторов, то есть может иметь какой угодно источник, за исключением независимых переменных. Последнее разграничение — между популяцией и выборкой. Популяция — это весь тот контингент людей, который интересует исследователя; а выборка — это группа людей, фактически включенных в исследование. При сравнении двух выборок (двух возрастов, двух полов, экспериментальных условий и т. д.) нас интересует вопрос, есть ли истинное различие между популяциями, из которых отобраны эти группы. Если бы нам удалось собрать данные по всей популяции, а не только по выборке, и исключить возможность погрешности измерения, у нас был бы ответ: полученные результаты и были бы результатами интересующей нас популяции. Однако, разумеется, сделать этого мы не можем; выборки — это всегда лишь часть популяции, измерение всегда неточно, и всегда существуют посторонние источники дисперсии. Именно поэтому нам необходимы методы оценки, или определения на основе логических заключений вероятности того, что выявленные различия между выборками отражают истинные различия между популяциями. Поясним сказанное выше на примере гипотетического исследования агрессии и вопроса различий между полами в уровне агрессии. Мы уже знаем, что различия между полами действительно есть, в том смысле, что показатели мальчиков и девочек неодинаковы. Однако мы знаем и то, что это различие может объясняться погрешностями измерения и побочными источниками дисперсии. Кроме того, мы наблюдали лишь небольшую выборку из популяции, которая нас интересует — только 60 детей из миллионов 3- и 4-леток, посещающих детские сады США, и только несколько часов из жизни этих детей. Возможно, понаблюдав за теми же детьми вновь, мы получили бы несколько отличные результаты. Возможно, что, понаблюдав вторую выборку из 60 детей, мы опять-таки получили бы иные результаты. И возможно, что если бы нам удалось понаблюдать всю интересующую нас популяцию, мы получили бы еще какую-то совокупность данных. Именно для определения вероятности всех этих «возможно» необходимы статистические показатели, выводимые логическим путем. В предыдущем абзаце цели использования статистических показателей, выводимых логическим путем, рассматриваются с двух позиций. Во-первых, с точки зрения воспроизводимости результатов или надежности. Получим ли мы одинаковые результаты, вновь и вновь производя один и тот же эксперимент? Во-вторых (что в действительности то же самое), с точки зрения перехода от выборки к популяции. Достаточно ли велико отличие, обнаруженное в выборке, чтобы доказать существование отличия в популяции? Как бы мы ни формулировали вопрос, нужно выбрать одно из двух: либо наши результаты действительно отражают положение вещей в популяции, либо они обусловлены действием случайных факторов, действующих в нашем конкретном исследовании. И как бы мы ни формулировали вопрос, использование статистических показателей, выводимых логическим путем, не дает однозначного ответа о том, что из сказанного верно; все, о чем мы можем судить по этим статистическим показателям — это о вероятности каждой из альтернатив. Это, фактически, главное, что нужно осознать в отношении статистических выводов: они вероятностны, а не абсолютны. Теперь обратимся к конкретному примеру статистического анализа. Рассмотрим вновь различия между полами в уровне агрессии. Нам нужно определить, отражает ли обнаруженное в исследовании различие истинное различие в популяции или же оно — результат случайности. Как уже отмечалось, в качестве примера, за основу мы возьмем логику статистического анализа при использовании f-критерия. Формула расчета f-критерия представлена ниже. Логика, положенная в основу этой аналитической проверки, довольно проста. Величина f-критерия, а следовательно, и вероятность того, что результаты неслучайны, зависит от трех факторов. Первый — разница между значениями средних. Чем больше различие, тем больше t. Второй — изменчивость внутри сравниваемых групп. Именно изменчивость представлена в довольно громоздком делителе. Чем она меньше, тем больше С. Наконец, третий фактор — объем выборки. Объем выборки влияет на конечный результат по двум направлениям. Во-первых, как можно заметить, проанализировав формулу, объем выборки влияет на изменчивость: чем больше п, тем меньше делитель. Во-вторых, даже подсчитав С, мы все еще должны определить, какова вероятность того, что это значение t - результат случайности. Эта вероятность зависит как от величины С, так и от объема выборки. Чем больше п, тем ниже вероятность того, что полученное значение t — всего лишь результат случайных колебаний.
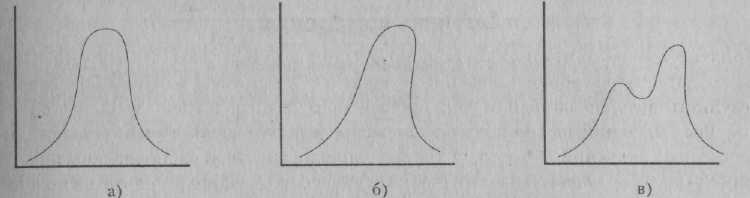
Применим теперь формулу t для оценки различий между мальчиками и девочками в нашем гипотетическом исследовании. Получаем t, равное 2,41. Обратившись теперь к таблице показателей Г-критерия (которая есть в любом учебнике по статистике), мы устанавливаем, что такое или большее значение С могло быть результатом случайности менее чем в 5 случаях из 100. Этот расчет вероятности случайности основан на том, что называется нуль-гипотезой — то есть предположении, что между группами в действительности нет различий. Результаты, вероятность случайного появления которых составляет менее 5 %, условно считаются статистически значимыми. Поэтому мы можем отвергнуть нуль-гипотезу об отсутствии различий между полами и заключить, что мальчики действительно агрессивнее девочек. Мы еще вернемся к понятию статистической значимости. Однако сначала стоит повторить логику анализа с использованием t-критерия, поскольку она применима в отношении ряда других статистических критериев. Как отмечалось, эта логика действительно довольно очевидна и сводится к трем правилам, основанным на простом здравом смысле: 1. Случайность больших различий между группами менее вероятна, чем случайность небольших различий. Поэтому разница между большинством других значений среднего арифметического из табл. 7.2 (например, между 3-летними девочками и 3-летними мальчиками) слишком мала, чтобы дать существенный t-показатель, и поэтому, скорее всего, объясняется случайностью. 2. Чем меньше внутригрупповая изменчивость, тем меньше вероятность того, что различия являются результатом случайности. Небольшое число существенных отклонений от группового среднего в ту или иную сторону практически не отражается на значении среднего арифметического. Этот фактор играет роль при сравнении результатов 3- и 4-летних мальчиков. Несмотря на существенную разницу между средними показателями, сравнение с использование f-критерия говорит об отсутствии значимых различий, в немалой степени из-за высокой изменчивости в группе 4-летних мальчиков. 3. Наконец, вероятность случайности различий, обнаруженных в больших выборках, меньше, чем вероятность случайности таких же различий в небольших выборках. Если количество испытуемых невелико, один или два крайне высоких или крайне низких показателя могут исказить среднее арифметическое; в больших выборках такие случайные колебания компенсируются. Этот фактор играет роль при сравнении результатов 3-летних и 4-летних мальчиков. Если бы объем выборки составлял 30, а не 15 человек на группу, то полученный показатель t был бы значим. Из сказанного выше следует, что цель использования статистических процедур, основанных на логических построениях, — установление статистической значимости. Важно ясно представлять, что подразумевается, а также, что не подразумевается под выражением «статистическая значимость». Вспомним для начала, что выводы, основанные на логических статистических показателях, носят вероятностный характер. Утверждение, что определенное различие средних статистически значимо, означает, что такое различие вероятнее всего не случайно, если исходить из нуль-гипотезы об отсутствии различий в популяции. Однако всегда есть вероятность ошибки. Первая состоит в ошибочном отвержении нуль-гипотезы, то есть в выводе о наличии некоего эффекта при его реальном отсутствии. Этот тип ошибки называют ошибкой первого рода. В нашем исследовании агрессии мы допустили бы ошибку первого рода, заключив, что мальчики и девочки различаются по уровню агрессии, в то время как в действительности на уровне популяции в целом такое различие отсутствует. Вероятность ошибки первого рода определяется уровнем вероятности, на котором мы отвергаем нуль-гипотезу. Если уровень вероятности 0,05, риск допустить ошибку первого рода составляет 5 из 100. Если уровень вероятпости ниже, скажем, 0,01 или 0,001, тогда, естественно, у нас гораздо меньше шансов ошибиться. - Второй тип ошибки состоит в принятии нуль-гипотезы тогда, когда в действительности имеется истинный эффект. Этот тип ошибки называется ошибкой второго рода. В исследовании агрессии мы допустили бы ошибку второго рода, если бы группы 3-летних и 4-летних детей различались, но мы заключили бы, что между ними нет различий. Вероятность ошибки второго рода рассчитать труднее, чем вероятность ошибки первого рода, и здесь мы даже не будем пытаться объяснить этот расчет. Однако замечу, что вероятность одной ошибки находится в обратной зависимости от вероятности второй ошибки, то есть чем выше вероятность одной, тем ниже вероятность другой. Исследователь, к примеру, может снизить риск ошибки первого рода, установив уровень вероятности 0,01, однако в то же время он существенно повышает риск ошибки второго рода. Отметим также, что психологи предпочитают минимизировать вероятность ошибки первого рода. Эта осторожность в позитивных выводах отражена в общепринятой норме: «значимыми» признаются только результаты, вероятность случайности которых составляет менее 5 %'. Розноу и Розенталь (Rosnow & Roscntal, 1989) критикуют позицию исследователей, целиком полагающихся на уровень вероятности 0,05: «Несомненно, Господь любит 0,06 ничуть не меньше, чем 0,05» (р. 1277). Рассмотрение ошибок первого и второго рода возвращает нас к понятию валидности. В главе 2 рассказывалось о трех из четырех основных форм валидности. Четвертая форма — валидность статистического вывода: точность статистического вывода, сделанного при анализе данных. Верны ли наши заключения о наличии или отсутствии связи между переменными? Избежав ошибочного вывода о существовании связи при ее отсутствии (ошибка первого рода) и об отсутствии связи при ее наличии (ошибка второго рода), мы достигаем валидности статистического вывода. Установив статистическую значимость, мы можем сказать, что наши результаты, вероятнее всего, не случайны. Важно отдавать себе отчет, что критерий значимости имеет отношение только к возможности случайных результатов. Значимость не исключает возможности искажения валидности. По этому критерию можно судить о наличии различий между двумя группами, но не о причинах различий. Рассмотрим различие между полами в нашем исследовании агрессии. Нас интересует вероятность того, чТо это различие в поведении истинно (однако, разумеется,, причин?.! его еще предстоит выявить). Но значимое различие вполне могло появиться и по другим причинам. Возможно, наши наблюдатели ожидали от мальчиков или от девочек большей агрессивности и поэтому в соответствующем направлении искажали результаты — отсюда различие, обусловленное необъективностью наблюдателей. Возможно, на девочках сильнее отражается присутствие наблюдателя, и поэтому они более склонны подавлять агрессию, когда за ними наблюдают, — отсюда различие, обусловленное дифференцированной реактивностью. Возможно, мы наблюдали девочек в начале года, а мальчиков позже, когда агрессия становится обычным явлением, — отсюда различие, обусловленное одновременным влиянием фактора принадлежности к определенной группе и фактора времени измерения. Суть в том, что любые из описанных в этой книге факторов, ставящих под сомнение валидность, могут все еще действовать, искажая наши результаты. Статистическая значимость не гарантирует общей валидности. Это лишь отправная точка, необходимое, но не достаточное условие для вывода о том, что мы обнаружили что-то существенное. И последнее замечание — статистическая значимость не гарантирует того, что результаты имеют некоторую научную ценность. «Значимость» в том смысле, в котором этот термин употребляется здесь, имеет отношение только к статистической вероятности, а не к теоретической или практической важности. Различие между полами в уровне агрессии может быть истинным, в том смысле, что оно не случайно и не обусловлено неудовлетворительной валидностью. Достаточно ли велико это различие, чтобы что-то значить — в отношении, например, того, как воспитатели должны вести себя с мальчиками и девочками, — отдельный вопрос. Важно помнить, что статистическая значимость различия зависит не только от величины разницы, но и от объема выборки. В достаточно большой выборке даже незначительное различие достигает уровня значимости. Мы еще вернемся к этому вопросу, когда будем рассматривать величину эффекта. Выбор статистического показателя Для многих студентов слово «статистика» ассоциируется с зазубриванием формул и бесконечными часами утомительных подсчетов. В действительности профессиональный исследователь если и может воспроизвести, то не более нескольких формул и тратит на расчеты совсем немного времени. В этом нет необходимости: формулы есть в учебниках или заложены в компьютер, а расчеты можно производить на калькуляторе, на компьютере (или предоставить это студенту-лаборанту!). Что значительно важнее, это знать, какого рода статистический анализ подходит и информативен для определенного рода данных. При выборе наиболее подходящего статистического показателя учитывается множество факторов. В этом разделе мы рассмотрим три из них: уровень, па котором измеряется зависимая переменная, распределение значений зависимой переменной и план исследования. Уровень измерения Понятие уровня, или шкалы измерения было введено в главе 4. Вспомним, что выделяют четыре уровня измерения: поминальный, или качественное обозначение результатов; порядковый, или ранжирование результатов по некой шкале количественных значений; интервальный, или распределение результатов по шкале количественных значений, которые не только упорядочены, но и равноудалены друг от друга; и уровень отношений, или равномерное упорядочение результатов по шкале количественных значений, имеющей абсолютный нуль. Уровень измерения является одним из факторов, определяющих, какой из статистических критериев уместнее всего употребить. Некоторые критерии, включая и t, используются только тогда, когда измерение производится на шкале интервалов или шкале отношений. Основание для этого требования станет очевидным при анализе формулы на рис. 7.1. Для расчета f-критерия мы должны произвести ряд арифметических операций с числами — сложить, а затем разделить, чтобы получить среднее, вычесть каждое число из среднего, чтобы' получить показатель отклонения и т. д. Эти операции имеют смысл только в том случае, если числа, с которыми мы работаем, являются точным отображением количественного значения, а не просто названиями или порядковыми номерами. Показатели частоты из табл. 7.1 отвечают указанному требованию, и, следовательно, к этим данным f-критерий применим. Однако f-критерий не подошел бы, если бы наши данные были основаны на описанной ранее рейтинговой шкале. Мы могли бы, к примеру, сложить рейтинговую оценку 5 («крайне агрессивный») с рейтинговой оценкой 1 («совершенно неагрессивный») и получили бы среднее 3 («умеренно агрессивный»). (Вскоре я уточню это замечание. Кроме того, необходимо помнить, что не все специалисты в области теории измерения и статистики сходятся во мнении по вопросу связи между шкалами измерения и статистическими показателями, — см. Cliff, 1993; Michell, 1986.) Распределение показателей Использование некоторых статистических критериев связано с определенными предположениями о распределении оцениваемых этим критерием показателей. В частности, так называемые параметрические критерии зависят от определенных предположений о распределении данных. Это, фактически, и является смыслом термина «параметрический»: статистический анализ зависит от валидности некоторых предположений в отношении «параметров» популяции, к которой принадлежит выборка. Рассмотренный выше t-критерий — пример параметрического критерия; критерий, используемый в дисперсионном анализе (ANOVA), которому посвящен следующий раздел, — еще один пример. Если говорить более конкретно, в основе использования большинства параметрических критериев лежит два допущения. Первое состоит в том, что показатели распределены по закону нормального распределения. Второе — что дисперсия в сравниваемых группах одинакова. Второе допущение распространяется не на все случаи, но применимо ко многим, часто используемым параметрическим критериям, включая -критерий и F-критерий дисперсионного анализа.
Рис. 7.1. Примеры нормального и ненормального распределения Мы уже обсуждали понятие дисперсии. Рассмотрим теперь необходимые условия нормального распределения. На рис. 7.1 (а) изображено нормальное распределение. Термин «нормальное распределение* используется в отношении классической колоколообразной кривой, к распределению, в котором среднее, медиана и мода совпадают, а показатели постепенно уменьшаются по мере удаления от этого центра. Рис. 7.1 (б) и (в), напротив, иллюстрируют распределение, явно отличное от нормального. Между уровнем измерения и распределением есть определенная связь. Показатели номинальных и порядковых шкал не могут иметь нормальное распределение. Что касается номинальной шкалы, в ней нет количественных значений, и поэтому вопрос распределения по шкале количественных значений не стоит; все, что здесь возможно, это подсчет частоты случаев в каждой из категорий. Если говорить о порядковой шкале, то нам неизвестна разница между показателями, а следовательно, и их распределение. Кроме того, в абсолютно упорядоченной шкале (то есть при отсутствии совпадений) на каждый уровень шкалы приходится всего по одному случаю; поэтому теоретически распределение будет плоским. Таким образом, необходимым условием нормального распределения является наличие шкалы отношений или интервалов. Тем не менее это недостаточное условие, поскольку кривая показателей все еще может выглядеть так, как на рис. 7.1 (б) или (в). Однако по закону нормального распределения могут быть распределены только показатели, соответствующие определенным шкалам. Мы только что рассмотрели предположения, лежащие в основе использования параметрических критериев t и F. Скажем теперь несколько слов об альтернативе Логика проверки с использованием критерия хи-кнадрат: определение того, насколько полученные значения частоты в каждой клетке таблицы отклоняются от ожидаемой частоты, если допустить отсутствие различий между группами.
, „ (фактическая частота — ожидаемая частота)2 Формула: У1= У----------------------------------------------------------'- л ожидаемая частота Х2= 23,42; уровень вероятности <0,01 Вывод: между мальчиками и девочками существуют значимые различия в предпочтении игрушек. Рис. 7.2. Иллюстрация аналитической процедуры с использованием критерия хи-кнадрат параметрических критериев, после чего можно будет сделать еще несколько замечаний относительно выбора статистического показателя. Как можно было ожидать, альтернативой параметрическим являются непараметрические критерии. Рисунок 7.2 служит иллюстрацией для широко используемого непараметрического критерия хи-квадрат. Гипотетические данные, представленные на рисунке, относятся к описанному ранее исследованию предпочтений игрушек; гипотетический результат состоит в том, что предпочтение определенных игрушек является функцией от пола1. Хи-квадрат используется при наличии номинальных данных, таких, как данные, представленные на рисунке, для которых f-критерий не подходит. Для каждого из четырех уровней измерения — номинального, порядкового, интервального и уровня отношений — существуют свои непараметрические критерии. Таким образом, этот подход имеет более широкое применение, чем использование параметрических критериев. Кроме того, непараметрические показатели не связаны с предположениями о виде распределения, которые лежат в основе параметрических показателей; поэтому непараметрические критерии применимы к данным, построенным на шкалах интервалов и отношений, но не удовлетворяющим параметрическим допущениям. (Из работ, посвященных непараметрическим критериям, можно назвать следующие: Gibbons, 1993; Marasculio&McSweeney, 1977; Siegel&Castellan, 1988.) По какому принципу осуществляется выбор между параметрическими и непараметрическими характеристиками? Как только что отмечалось, в ряде случаев выбора просто нет, поскольку единственный вариант — это непараметрический Формулу, представленную на, рисунке, называют «определительной формулой* хи-квадрат. Есть также «калькуляционная формула»: равноценная в математическом смысле, но более удобная для проведения расчетов. Формулы многих статистических показателей также разделяются на определительные и калькуляционные. критерий. В других случаях необходимо принять решение, и здесь приобретает значение несколько понятий. Рассмотрим два из них: мощность и устойчивость. Термин мощность означает вероятность того, что определенный логический критерий исключит нуль-гипотезу тогда, когда ее действительно нужно исключить. Чем мощнее критерий, тем лучше он выявляет истинные различия и поэтому позволяет безошибочно отвергнуть нуль-гипотезу. Это понятие, вероятно, кажется знакомым, поскольку мощность — это еще один способ охарактеризовать ошибку второго рода. Чем мощнее критерий, тем меньше вероятность ошибки второго рода. В некоторых случаях параметрические критерии мощнее аналогичных непараметрических критериев. По сути, это объясняется тем, что при расчете параметрического критерия используется больше информации о данных. Многие непараметрические критерии, например, ограничены порядковыми характеристиками данных, в частности, рангом показателей в сравниваемых выборках. При расчете f-критерия, напротив, задействуются фактические показатели и абсолютная разница между ними; поэтому иногда с его помощью выявляются различия, которые не смогли выявить непараметрические критерии. Следует добавить, что разница в мощности, как правило, невелика и обнаруживается преимущественно при изучений больших выборок. Кроме того, она не является чем-то неизбежным. Во многих ситуациях параметрические и непараметрические критерии обладают одинаковой мощностью. Если предположения, лежащие в основе параметрического критерия, серьезно нарушаются, непараметрические аналоги могут оказаться более мощными (см. Blair & Higgins, 1980). Сказанное о параметрических предположениях подводит нас к понятию устойчивости. Устойчивость характеризует безопасность отклонений от допущений, лежащих в основе некоего критерия. Устойчивый критерий сравнительно нечувствителен к таким нарушениям, то есть, как правило, он позволяет сделать точные выводы о значимости даже тогда, когда допущения не соответствуют действительности. И t и f-критерии достаточно устойчивы. Именно поэтому в литературе можно часто встретить указание на их использование даже для данных, не отвечающих рассмотренным выше требованиям — данным рейтинговых шкал, к примеру, или данных, распределение которых заметно отличается от нормального, или при наличии неравной дисперсии у сравниваемых групп. Устойчивость не означает, что исследователь может, не задумываясь, применять параметрические критерии к любому типу данных; однако не следует и слишком поспешно отказываться от параметрических критериев лишь потому, что некое допущение, лежащее в их основе, нарушается. Возможно, стоит посоветоваться со специалистом: применим ли выбранный параметрический показатель к имеющимся данным? План исследования Мы рассмотрели две детерминанты выбора статистического показателя: уровень измерения и распределение данных. Третий фактор, который следует учитывать, — это план исследования. Имеют значение разные аспекты плана. Один из аспектов — количество уровней независимой переменной. В нашем примере с агрессией детей дошкольного возраста этот фактор довольно прост: две возрастные группы и два пола. Поэтому здесь достаточно легко при сравнении двух уровней каждой переменной можно применить f-критерий. Предположим, однако, что мы усложняем ситуацию, добавляя дополнительные уровни. Поскольку с полом представить это себе довольно трудно, включим новые возрастные группы. Допустим, вместо двух у нас их шесть. Что происходит тогда с нашим /-критерием? Наиболее очевидным следствием является то, что возникает необходимость подсчитать значительно большее количество критериев. При наличии шести возрастных групп возможно 15 парных сравнений. Поэтому, чтобы что-то обнаружить, придется подсчитать значение 15 t-критериев. Рассчитывать 15 показателей и указать их все в отчете, естественно, довольно неудобно. Однако более серьезный довод против этого имеет отношение к уровню вероятности. Нам нужно, чтобы этот уровень оставался неизменным, какой бы рубеж для значимости мы ни выбрали — к примеру, традиционные 0,05. Однако наличие множества Сделает интерпретацию уровня вероятности весьма затруднительной. Получив 15 значений, каждое из которых находится на уровне 0,05, мы получаем вероятность того, что значимость по крайней мере одного из этих показателей носит случайный характер, равную 0,54.' Как же тогда интерпретировать любой статистически значимый результат? Проблема, в действительности, даже еще сложнее. Вероятность 0,54 основывается на предположении, что все 15 показателей независимы друг от друга. Однако, как правило, это не так; они взаимосвязаны в том смысле, что одни и те же данные используются для разных сравнений. Это, фактически, относится к описанному выше случаю сравнения между возрастными группами: каждая из шести возрастных групп вносит свои данные — одни и те же — в расчеты 5 из 15 критериев. При наличии такого рода взаимозависимости критериев определить точный уровень вероятности для каждого критерия невозможно. Исследователь может подсчитать значение какого-то t и выявить значимость на уровне 0,05; однако вполне может оказаться, что истинный уровень значимости совершенно иной. Есть и еще одна проблема, связанная с множественностью t. Допустим, что мы усложнили наше исследование не добавлением уровнейяезависимой переменной, а введением дополнительных независимых переменных. Помимо возраста и пола как детерминант агрессии мы могли бы изучать эффект обстановки игровой комнаты, разницу между поведением в группе и на улице, влияние показа половине детей агрессивного мультика и т. д. Ясно, что чем больше независимых переменных, тем большее количество t нужно подсчитать. Но проблема состоит не только в избытке показателей L При изучении множественных переменных всегда существует вероятность зависимости эффекта одной переменной от уровня другой. Иными словами, возможно взаимодействие переменных. Эффекты взаимодействия необходимо выявить, но это довольно трудно сделать, используя только г-критерий. Чаще всего в качестве альтернативы использования t-критерия проводят дисперсионный анализ (ДА). По существу, ДА расширяет возможности г-критерия на те случаи, когда имеется более двух средних. Метод расчета здесь иной и более Возможно, проще всего увидеть то, откуда появляется такая вероятность, это задаться вопросом, ка-коны шансы не получить случпнный результат. При применении олной статистической проверки вероятность избежать такой ошибки составляет 0,95. При проведении диух отдельных проверок вероятность избежать ошибки определяется значением двух значений вероятности, то есть 0,952. При проведении 15 проверок эта вероятность составит 0,9515 или 0T4G. Поэтому кероятность того, что мы получим хотя бы один случайный значимый результат, равна 1 - 0,46. сложный, чем метод расчета t, и в этой книге мы даже не будем пытаться его описать. Однако логика, лежащая в основе обоих приемов, одинакова: мы проверяем значимость, определяя, насколько первичная дисперсия, связанная со сравниваемыми группами, превышает вторичную дисперсию или дисперсию ошибки. Статистический показатель, являющийся результатом этой проверки, обозначается буквой F, и значимость его, как и значимость t, устанавливается по стандартным таблицам, которые можно найти в любом учебнике по статистике. Рассмотрим, как можно было бы применить ДА в исследовании агрессии. У нас две независимые переменные: возраст и пол. Чтобы более наглядно продемонстрировать преимущества ДА перед использованием t, предположим, что в действительности, переменная возраста имеет б уровней, а не 2, как указанно в табл. 7.1. Применение ДА дает показатель F д.ля каждой из независимых переменных, или значения главных эффектов. Если для пола F значим, тогда в отношении этой переменной наши действия завершены; поскольку переменная пола имеет только два уровня, мы можем просто посмотреть на средние значения, чтобы определить, в чем состоит эффект. Значимый главный эффект для возраста — более сложный случай. Здесь показатель F основан на одновременном сравнении всех шести возрастных групп, а установление значимости подразумевает, что значим результат, по меньшей мере, одного парного сравнения. Тогда нам нужно использовать дополнительные критерии с тем, чтобы определить, результат какого из сравнений (или результаты каких сравнений) обладает значимостью. Эти дополнительные критерии сходны с f-критерием, однако их подсчет несколько проще и производится, только если общий показатель Освидетельствует о наличии значимого эффекта. Результатом ДА является также третий показатель F — для взаимодействия между возрастом и иолом. В целом, ДА дает столько F, сколько в исследовании существует возможных комбинаций независимых переменных. Если, к примеру, в исследовании 3 независимые переменные, результатом ДА будет четыре F, указывающих на взаимодействие: по одному на каждое парное сочетание и одно для тройного сочетания. Как и в случае со значимым главным эффектом, значимость Взаимодействий можно проверять при помощи специальных критериев для выяснения основы эффекта взаимодействия. Для выбора статистического показателя важен еще один аспект исследовательского плана. До этого момента мы говорили в основном о межсубъектных планах — то есть случаях, когда данные каждого испытуемого попадают только в одну категорию сравниваемых условии или групп. Но, как мы знаем из главы 3, многие независимые переменные изучаются при помощи внутрисубъектных планов, в которых данные каждого испытуемого попадают в категорию данных по каждому из экспериментальных условий. Что происходит со статистическими показателями, когда каждый испытуемый представлен в каждом из условий? Ответ довольно прост: мы переходим от межсубъектных критериев, которые рассматривались до этого момента, к соответствующим внутрисубъектным критериям. В действительности, для каждого межсубъектного критерия, о которых мы говорили выше, существует свой внутрисубьектный аналог. К примеру, есть внут-рисубъектньш f-критерий, а также внутрисубъектный дисперсионный анализ или дисперсионный анализ с повторными измерениями. Таблица 7.3 IQ и результаты по тесту достижения в выборке 5-классников
Кроме того, существуют непараметрические критерии, подходящие для виутрисубъектных данных (например, критерий изменения Макнемара, использование которого заключается в измерении нескольких хи-квадратов). Логика этих статистических процедур сходна с логикой использования межсубъектных критериев; однако в большинстве внут-рисубъектных проверок анализируется действительная разница между показателями (например, результаты некоего испытуемого в условиях 1 минус его же результаты в условиях 2). Поскольку в центре вниманий находятся показатели различия, данные критерии применимы не только для исследовательских планов с реальными повторными измерениями, но и для случаев, когда для каждого испытуемого в одних условиях подбирается соответствующий испытуемый в других условиях. Следует сделать еще одно замечание, касающееся внутрисубъектных показателей, Оно повторяет то, что было сказано в главе 3 при обсуждении относительных преимуществ внутри- и межсубъектных планов. Тогда мы отметили, что внутри-субъектные критерии, как правило, обладают большей мощностью, чем аналогичные межсубъектные критерии.
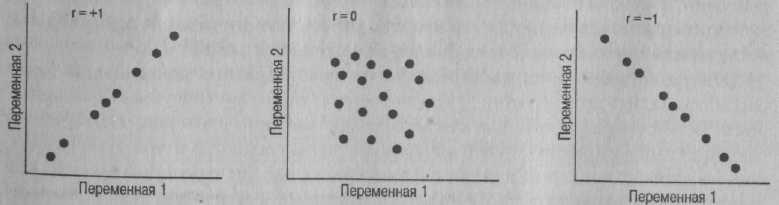
Рис. 7.3. Диаграммы рассеяния, иллюстрирующие корреляции разного уровня Это обусловлено уменьшением вторичной дисперсии, связанной с индивидуальными различиями испытуемых. Если в каждое из экспериментальных условий ставятся одни и те же испытуемые, вероятность внесения нежелательной дисперсии в результаты группового сравнения, обусловленные индивидуальными различиями, снижается. Большая мощность — одно из оснований для выбора между внутрисубъектными и межсубъектными подходами. Меры связи До этого момента основное внимание уделялось процедуре выявления различий между группами. Однако это не единственная область применения статистических процедур. Возьмем, к примеру, исследование, в котором были получены данные, представленные в табл. 7.3. Нас интересует вопрос, есть ли связь между IQ и успешностью выполнения стандартного теста достижения. Что нам нужно сделать? Для данных из табл. 7.3 подходит корреляционный статистический показатель. Корреляция — это мера связи между двумя переменными. Как мы узнали из главы 3, значение корреляционного показателя находится в пределах от +1 до -1. Коэффициент корреляции равный +1 свидетельствует о наличии абсолютно положительной связи между переменными, коэффициент корреляции равный 0 свидетельствует о полном отсутствии связи, а коэффициент корреляции равный -1 указывает на наличие абсолютно отрицательной связи. Эти варианты иллюстрируют графические изображения на рис. 7.3. Корреляционный показатель отличный от нуля свидетельствует о положительной или отрицательной связи, при этом сила связи увеличивается с приближением значения к + 1 или -1. О чем же говорят данные, представленные в табл. 7.3? Для определения меры связи мы должны сначала выбрать соответствующий корреляционный показатель, поскольку для вычисления корреляции существует множество разных методов. Как и в случае с логическими критериями, выбор метода зависит от наших предположений относительно характера данных. Чаще всего используются два показателя: коэффициент корреляции произведения моментов Пирсона и коэффициент корреляции рангов Спирмена. Статистический показатель Пирсона — это параметрический критерий, использование которого основано на тех же допущениях, что и использование остальных параметрических критериев — а именно на допущении, что измерение происходило по шкале интервалов или отношений, а данные распределены по закону нормального распределения1. Корреляционный показатель Спирмена — непараметрический критерий, основанный исключительно на порядковых характеристиках данных, и поэтому применяется чаще, чем критерий Пирсона. Оба показателя, надо заметить, зависят от другого важного предположения: что связь между переменными линейная. Если связь иного рода (к примеру, криволинейная, то есть при изменении значения одной переменной значение другой переменной сначала увеличивается, а затем уменьшается), стандартный корреляционный критерий неприменим. В действительности гсам по себе, как дескриптивный показатель, является непараметрическим, нако определение его статистической значимости зависит от параметрических предположений.
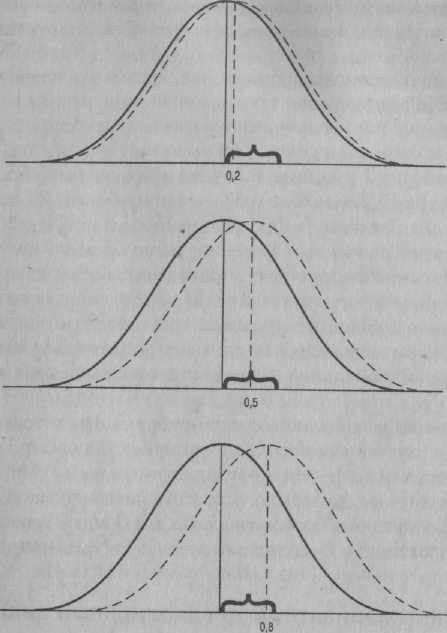
Поскольку использование критерия Спирмена проиллюстрировать легче, применим его для данных табл. 7.3. Формула коэффициента Спирмена, а также применение ее к нашим данным представлены на рис. 7.4. Проанализировав формулу, можно заметить, что коэффициент Спирмена — это мера общности рангового порядка пар показателей двух распределений. Если согласованность рангов полная, тогда, при отсутствии показателей отклонения, вычитаемое будет равно нулю, а коэффициент корреляции +1. Чем чаще и сильнее показатели отличаются по рангу, тем дальше от единицы будет корреляционный показатель. В нашей выборке данных коэффициент корреляции между IQ и результатами теста достижений равен 0,7, что свидетельствует о достаточно тесной, но не абсолютной связи. Стоит отметить, что применение к этим данным корреляционного анализа Пирсона даст очень близкое значение: 0,71. Фактически для большинства данных значения коэффициентов Спирмена и Пирсона очень близки. О чем говорит наличие корреляции между двумя переменными? Корреляция, как и среднее арифметическое или медиана, — дескриптивный статистический показатель, характеризующий, однако, не центральную тенденцию, а связь между переменными. Прежде чем интерпретировать значение коэффициента корреляции, необходимо проверить его статистическую значимость. Нуль-гипотеза при такой проверке заключается в том, что коэффициент корреляции между двумя переменными равен нулю; вопрос состоит тогда в том, есть ли значимое отклонение полученного коэффициента корреляции от нуля. Ответить на этот вопрос достаточно просто, поскольку в учебниках по статистике содержатся таблицы, по которым непосредственно можно установить уровень вероятности для любых коэффициентов корреляции (многие компьютерные программы также осуществляют подсчет уровня вероятности). На значимость влияют и величина коэффициента корреляции, и объем выборки; с их повышением растет вероятность значимости. Из таблицы явствует, что коэффициент корреляции равный 0,7 в выборке объемом 16 (то есть при наличии 16 пар показателей) значим на уровне 0,01; таким образом, между IQ и уровнем достижений действительно имеется связь. Значимость важна, но это лишь половина дела. Вспомним, что нас интересует не только существование связи, но и ее сила. Как правило, силу корреляционной связи интерпретируют с точки зрения точности прогноза; зная результаты испытуемого по одной переменной, насколько точно мы сможем предугадать его результаты по другой переменной? При корреляционном показателе, равном пулю, отношения между переменными носят случайный характер, и знание одного показателя не дает нам возможности предсказать другой показатель. По мере отклонения коэффициента корреляции от нуля его прогностическая способность возрастает, достигая максимума при коэффициенте корреляции равном ±1. Другой (равноценный) способ рассмотрения корреляции — с точки зрения доли объясняемой дисперсии. Используя показатели по одной переменной для прогноза показателей по второй переменной, мы «объясняем», в статистически-прогностическом смысле, определенную долю дисперсии значения второй переменной. Чем выше коэффициент корреляции, тем большая доля дисперсии получает объяснение. Эту закономерность можно определить точнее. Если коэффициент корреляции — пйреоновский г, доля объясняемой дисперсии составляет/3. Таким образом, коэффициент корреляции между IQ и уровнем достижений равный 0,71 означает, что вариации одного показателя объясняют 50 % вариаций другого. Последнее из утверждений ограничивает нас в наших интерпретациях. Коэффициент корреляции равный 0,71 довольно высок, однако даже при таком значении половина дисперсии все еще не получает объяснения. С приближением коэффициента корреляции к нулю доля объясняемой корреляции уменьшается, и довольно стремительно. Коэффициент корреляции равный 0,5 объясняет 25% дисперсии, а коэффициент корреляции равный 0,3 — лишь 9% дисперсии. Сказанное выше напоминает нам о разнице между значимостью и ценностью. Коэффициент корреляции может быть статистически значим, но в то же время столь мал, что его теоретическая или практическая ценность будет минимальна. Вероятность таких статистически значимых, но в действительности незначительных статистических показателей особенно велика при изучении больших выборок. В выборке объемом 50 коэффициент корреляции 0,27 достигает значимости на уровне 0,05. В выборке объемом 100 единиц значимостью обладает уже коэффициент корреляции 0,19. Помимо объема выборки при оценке коэффициента корреляции важно учитывать диапазон значения переменных. Здесь могут возникнуть две проблемы. Чаще всего, это проблема, о которой говорилось в главе 46, сужение диапазона, которое происходит тогда, когда значения одной переменной так близки друг к другу, что разница между ними не связана с дисперсией значений других переменных. Предположим, сравнивая IQ и уровень достижений, мы решили ограничить выборку детьми из классов для «одаренных». Как правило, отбор в эти классы производится по критерию IQ, в нашем случае он соответствует, скажем, 130 пунктам и выше. Решение сосредоточиться исключительно на очень высоких IQ означает, что мы резко сужаем диапазон дисперсии значений одной из наших переменных; вместо 60-70 пунктов диапазон IQ будет составлять лишь около 20. При такой скученности показателей IQ разница между ними вряд ли обнаружит существенную связь с любым параметром, включая разницу в уровне достижений. Возможно также, что диапазон значений переменной будет слишком широк. Допустим, от одного испытуемого к другому IQ изменяется на 20 пунктов: начиная с ребенка, имеющего IQ = 40, следующего ребенка с показателем IQ = 60 и т. д. до восьмого ребенка, обладающего IQ= 180. При столь большом разбросе велика вероятность того, что IQ будет значимо и существенно коррелировать практически со всеми показателями, которые мы измерим в нашей выборке. Сомнительно, однако, что величина таких коэффициентов корреляции будет иметь для нас большой смысл. Слишком узок или слишком широк диапазон значений, в основе проблемы лежит недостаточная внешняя валидность. Для того чтобы коэффициент корреляции был для нас интересен, он должен характеризовать не только выборку, для которой был подсчитан, но и всю популяцию, которую представляет эта выборка. Поэтому выборка должна быть репрезентативна — как по параметрам центральной тенденции, так и по параметру диапазона дисперсии — в отношении популяции, частью которой она является, Если выборка будет нерепрезентативна, полученные при ее изучении коэффициенты корреляции не будут обладать достаточной внешней валидностью. Альтернативы и более сложные варианты дисперсионного анализа В этом разделе мы вернемся к вопросу сравнения групп. Не будет преувеличением сказать, что, по крайней мере последние 50 лет, дисперсионный анализ является самым распространенным методом такого сравнения. Однако, несмотря на свою популярность, ДА — не всегда предпочтительный вариант статистического анализа, даже в случаях, когда предположения, лежащие в его основе, справедливы. Есть ситуации, в которых более полное представление о полученных результатах дают другие формы анализа. В этом разделе мы кратко рассмотрим ряд таких ситуаций и соответствующие статистические процедуры. Еще менее чем в предыдущих разделах изложение претендует на полноту; цель заключается лишь в том, чтобы дать читателю возможность понять или переосмыслить разнообразные варианты более глубокого анализа и основания для его использования. Плановые сравнения Ранее мы отметили проблемы, возникающие при множественности значений t-критерия, следствием которых является необходимость использования дисперсионного анализа, позволяющего осуществить обобщенную проверку на наличие или отсутствие значимых-эффектов. Однако обобщенные проверки не всегда облада- ют преимуществом. ДА более всего подходит для тех случаев, когда у исследователя нет четких гипотез и ему скорее хочется выявить любые интересные результаты, которые может дать исследование. В подобных случаях такая комплексная проверка, как ДА, предпочтительнее множества одиночных проверок. Однако в некоторых исследованиях имеются четкие гипотезы, и основная цель проведения статистической проверки состоит в получении ясного ответа в отношении каждой из гипотез. В таких случаях ДА малоэффективен, поскольку эта форма анализа включает сравнения, которые могут и не интересовать исследователя, тем самым снижая эффективность сравнения того, что действительно интересно. Рассмотрим пример (взятый из работы Hays, 1981). Нас интересует влияние обучения детей на их ответы при использовании нравственных дилемм Колберга (см. главу 12). Мы используем две формы обучения детей: наблюдение за взрослым, дающим ответы, которые соответствуют более высокому нравственному уровню, и обсуждение вопросов нравственности в группе сверстников. Нам также интересен возможный эффект сочетания двух типов обучения, поэтому мы включаем третье экспериментальное условие, при котором дети и наблюдают за отвечающим взрослым, и проводят обсуждение в группе. Мы знаем, что для оценки эффекта обучения необходима контрольная группа; поэтому четвертое условие состоит исключительно в претесте и посттесте, без каких-либо экспериментальных вмешательств. Однако нас беспокоит, что наблюдение образца поведения или внутри-групповое взаимодействие могут сами по себе повлиять на ответы, вне зависимости от нравственного развития, которое мы изучаем. Поэтому мы включаем еще два контрольных условия; одно — при котором дети наблюдают взрослого, рассуждающего о чем угодно, кроме нравственных проблем; и второе — при котором дети обсуждают любую тему, не касающуюся нравственности. В таком исследовании нас в действительности не интересует главный эффект каждого из условий, эффект, который может быть обусловлен значимой разницей ¦ между любыми из возможных пар средних значений. Наш интерес более специфичен и ограничен сравнениями между средними значениями, которые важны для исследования. Мы, к примеру, захотим выяснить, отличается ли на уровне значимости каждое из экспериментальных условий от соответствующего ему контрольного, а также, различаются ли между собой три экспериментальных условия. Эти сравнения действительно имеют смысл. В других сравнениях гораздо меньше смысла — к примеру, бессмысленно сравнивать экспериментальное условие группового обсуждения и контрольное условие наблюдения поведения взрослого. Обобщенный дисперсионный анализ объединяет все эти сравнения. Конечно, можно начать с проверки f-критерия, а затем использовать отдельные дополнительные критерии для интересующих нас сравнений-. Однако существует риск, что главный эффект F не будет обладать значимостью, и в этом случае у нас не будет реальных оснований для дополнительных проверок. Кроме того, критерии, используемые после получения значимого результата при дисперсионном анализе, обладают меньшей мощностью, что означает риск упустить из вида действительно важный эффект. Альтернативой ДА в таких случаях служат плановые сравнения, когда мы заранее определяем, какие из средних значений будем сравнивать, и производим толь- ко эти сравнения. В нашем гипотетическом исследовании обучения, к примеру, мы могли бы провести сравнение экспериментальных воздействий,, оставив без внимания другие сравнения. Разъяснение методов проведения такого избирательного сравнения не входит в намерения автора; описание их можно найти в большинстве учебников по статистике (например, Hays, 1981). Разумеется, такой подход влечет потерю некоторой информации. Однако если мы точно знаем, что нас интересует, потеря будет минимальной. А поскольку критерии, используемые в предварительно спланированных проверках, обладают большей мощностью, чем критерии post-hoc, наши шансы получить ясные вопросы на интересующие нас вопросы выше. Важно подчеркнуть, что плановые сравнения действительно подразумевают планирование и избирательность; то-есть мы не можем сравнивать что.угодно. Каким должно быть количество сравниваемых пар — на этот счет специалисты в области статистики не имеют единого мнения. Одни из них рекомендуют ограничивать плановые сравнения статистически независимыми, или «ортогональными», парами. Количество таких независимых пар на одну меньше количества средних значений; в нашем исследовании обучения оно будет составлять 5 независимых сопоставлений (в упоминавшейся выше работе объясняется, как определить независимость сопоставлений (Hays, 1981)). Другие специалисты являются приверженцами несколько более либерального подхода, говоря о том, что интересные с теоретической точки зрения пары можно проверить даже при отсутствии полной их независимости. В работе Кеппел (Keppel, 1991) можно найти полезную информацию о разных точках зрения, а также ряд методов корректировки уровня вероятности в случаях, когда производятся множественные или частично пересекающиеся сравнения. Величина эффекта Цель плановых сравнений состоит в выявлении эффектов, которые могут упустить такие глобальные проверочные процедуры, как ДА. Процедура измерения величины эффекта снимает некоторые из ограничений ДА. В этом случае мы предполагаем, что при анализе был обнаружен значимый эффект; тогда встает вопрос, насколько он велик. Насколько сильна связь между зависимыми и независимыми переменными? Чтобы разобраться в этом вопросе, нужно вспомнить то, о чем мы говорили ранее, обсуждая термин «статистическая значимость». Установление факта статистической значимости свидетельствуете наличии и некой неслучайной связи между переменными. Факт наличия значимости ничего не говорит о силе этой связи. О масштабах эффекта можно, конечно, догадываться по средним значениям; большая разница между средними, очевидно, отражает более значимый эффект, чем Меньшая разница. Но есть ли более точная мера величины эффекта? j Ответ состоит в том, что сегодня для расчета величины эффекта существует ряд методов. Основные работы, в которых дается описание этих методов, следующие: Коэн (Cohen, 1977), Розенталь (Rosenthal, 1994b) и Тацоука (Tatsouka, 1993). Здесь я опишу простейшую из процедур, разработанную Коэном (Cohen, 1977). Согласно этому подходу, величина эффекта, или d, определяется как разница между двумя средними, разделенная на стандартное отклонение в сравниваемых группах. Таким образом, учитывается средняя разница, которая оценивается с точки зрения изменчивости показателей. Чем меньше изменчивость, тем существеннее средняя разница. Сейтц (Seitz, 1984) приводит пример. Стандартное отклонение в большинстве тестов IQ равно 15. Средняя разница между группами, равная 12, (каковой она, к примеру, указывается в исследовательских отчетах для только что поступивших в колледж и докторов философии) означала бы величину эффекта 0,8, если бы средняя разница составляла 7 пунктов, величина эффекта была бы равной 0,2. Для интерпретации этих величин можно графически изобразить распределение показателей двух популяций и область их пересечения. На рис. 7.5 изображены кривые, соответствующие трем описанным выше ситуациям, Заметьте, что с возрастанием величины эффекта сокращается область совпадения. Как отмечает Сейтц\ средняя пара кривых особенно информативна. Средняя разница 7 пунктов — или, если рассматривать ситуацию в общем виде, разница, составляющая половину стандартного отклонения, — может показаться не слишком большой. Однако эта разница означает, что 70% одной популяции имеет показатели выше среднего другой популяции. Меры величины эффекта дают полезную информацию, которую нельзя извлечь непосредственно из значений логических критериев. Однако до сих пор в исследовательских отчетах в области психологии развития — а в действительности и в психологии в целом — редко можно встретить указания на величину эффекта (Cohen, 1994). При обзоре любого журнала по психологии развития можно обнаружить не один десяток F и t, но лишь несколько скромных попыток рассчитать формальные показатели величины разнообразных эффектов. Мультивариантный дисперсионный анализ Разница между одновариантными и мультивариантными статистическими процедурами довольно расплывчата; разные специалисты определяют ее по-разному. Однако наиболее распространенным критерием служит количество зависимых переменных. Если анализ проводится при наличии одной зависимой переменной, его можно назвать одновариаптным. Процедура использования r-критерия и дисперсионный анализ — одновариантные статистические процедуры. Если в анализе задействуется более одной зависимой переменной, его можно назвать мульти-вариантным. Существует ряд мультивариантных статистических процедур, к которым относится и мультивариантный дисперсионный анализ, или МДА. Использование мультивариантных статистических процедур — явление, получившее широкое распространение в психологических исследован иях совсем недавно. Как отмечает Сейтц (Seitz, 1980), статистические основы для этих процедур были выработаны уже давно; проблемы начинались при их практическом использовании. Расчеты мультивариантных статистических показателей зачастую чрезмерно сложны и громоздки, и поэтому до появления компьютеров и соответствующих компьютерных программ использование мультивариантных статистических процедур было крайне затруднено. Наличие компьютера и навыки работы на нем могут оказаться весьма ценными для проведения любой формы статистического анализа.
Рис. 7.5. Разница между популяциями, соответствующая разным значениям величины эффе Расчеты — не единственная сложность, связанная с мультивариантными статистическими процедурами. В определенном смысле, расчеты — самое простое, поскольку эту работу выполняет компьютер. Настоящая проблема — определить, когда необходим мультивариантный анализ и как интерпретировать его результаты. Для ответа на эти вопросы написано множество книг и прочитано множество теоретических курсов, в том числе весьма подробных и содержательных (см., например: Hair, Anderson, Tatham & Black, 1992; Morrison, 1990; Nesselroade & Cattell, 1988). Здесь я затрону лишь несколько моментов, о которых ведется речь в более сжатой работе (Applebaum & McCall, 1983), ориентированной на специалистов в области психологии развития. Предположим, проведено исследование с двумя или более зависимыми переменными. Как узнать, нужно ли проводить отдельный ДА для каждой из переменных (этот вариант всегда необходимо учитывать) или объединить их все в МДА? Эпплбаум и Маккол говорят о двух основных преимуществах МДА перед ДА. Одно из них сходно с преимуществом F-крнтерия перед отдельными f-критерия-ми. Чем больше проверок с помощью дисперсионного анализа мы проводим, тем выше вероятность, что некоторые эффекты достигнут уровня статистической зна- чимости чисто случайно. При проведении МДА уровень вероятности при любых сравнениях, напротив, сохраняется постоянным. Второе преимущество имеет отношение к возможности при проведении МДА использовать информацию о связи между зависимыми переменными, информацию, которая не учитывается при ДА, когда анализ каждой переменной производится отдельно. Одновременный учет всех переменных, среди прочего, означает, что при помощи МДА иногда можно выявить значимые эффекты, которые упускает ДА. Как следует из вышесказанного, МДА уместно использовать только тогда, когда есть основания предположить, что между зависимыми переменными существует некая интересная связь. Как пишут Эпплбаум и Маккол (Applebaum & McCall, 1983): «Вы не включаете в МДА все имеющиеся переменные, лишь бы увидеть, что из этого получится. Зависимые переменные нужно осмысленно подбирать. Они должны образовывать логическую совокупность, которую можно интерпретировать именно как совокупность* (р. 435). Затем Эпплбаум и Маккол приводят в качестве примера исследование габитуации у младенцев, в котором зависимые переменные представляют собой следующее: длительность фиксации в первой пробе, пробу с наиболее длительной фиксацией, количество проб от самой длительной к самой непродолжительной фиксации и средняя длительность фиксации в одной пробе. Эти переменные образуют совокупность связанных между собой (но не дублирующих друг друга) показателей габитуации у младенца, для анализа которой больше подходит МДА, а не ДА. В целом, для использования МДА больше всего подходит ситуация, когда исследование включает ряд несколько различающихся между собой характеристик одного и того же конструкта (как в примере с габитуацией). Как бы ни было кратко это изложение метода МДА, из него можно вынести главную мысль. Наличие мощной статистической процедуры — и компьютерной технологии для ее осуществления — не означает, что эту процедуру можно бездумно использовать для любого типа данных. Сутью грамотной статистической работы является знание того, какой статистический прием применим к разного рода данным и планирование исследования с целью достижения оптимального соответствия статистических процедур и данных. Множественный регрессионный анализ Как и МДА, множественный регрессионный анализ — сложная статистическая процедура — сложная как для проведения, так и для описания. Как и в случае с МДА, на двух-трех страницах излагать суть процедуры множественного регрессионного анализа бессмысленно. Однако регрессионный анализ стал использоваться столь широко, что краткое рассмотрение его принципов представляется оправданным. Говоря словами Керлингер (Kerlinger, 1986), множественный регрессионный анализ — «это метод изучения результатов влияния и силы влияния более чем одной независимой переменной на одну зависимую переменную с использованием принципов корреляционного и регрессионного анализа» (р. 527). Если выразиться несколько иначе, множественный регрессионный анализ дает нам информацию о том, как связаны две или более независимые переменные, или «предикторы», с одной зависимой переменной, или «критерием». Мы, к примеру, можем провести исследование, в котором будем изучать успешность выполнения, в лабораторных условиях некоего задания как функцию от IQ, социально-экономического статуса, характера инструкций к заданию и времени, отведенного на его выполнение. Применение множественного регрессионного анализа к нашим данным позволит оценить вклад каждого из этих четырех предикторов (как но отдельности, так и в сочетании) в дисперсию критериальной переменной. Между регрессионным и корреляционным анализом, описанным ранее в этой главе, существует тесная связь. В обоих случаях мы используем значение одной переменной у некоего испытуемого для предсказания значения другой переменной. Как следует из факта включения таких параметров, как IQ и социально-экономический статус, еще одно сходство состоит в возможности использования в регрессионном анализе переменных, которые, с точки зрения исследовательского плана, являются корреляционными, в том смысле, что они просто измеряются, а не подвергаются экспериментальным манипуляциям. Много общего у регрессионного анализа и с дисперсионным анализом. Эти процедуры имеют одни и те же цели: определить влияние, совокупности независимых переменных на некую зависимую переменную, как по отдельности, так И во взаимодействии. Регрессионный анализ в предыдущем примере можно было бы заменить дисперсионным анализом четырех переменных, результатом которого было бы значение четырех F, указывающих на главный эффект, а также ряд значений F для взаимодействий. В действительности это правило носит общий характер: большинство задач, которые решает множественный регрессионный анализ, можно решить с помощью дисперсионного анализа. Однако, как отмечают многие авторы, из двух процедур множественный регрессионный анализ обладает более широкими возможностями, поскольку ДА — это лишь частный случай регрессионного анализа. Поэтому любую задачу, которую может решить многофакторный ДА, может решить и множественный регрессионный анализ. - Если учесть широкие возможности множественного регрессионного анализа, можно задаться вопросом, какие факторы могут заставить нас предпочесть его ДА при анализе некой совокупности данных? Отмечу вначале, что зачастую это дело вкуса, поскольку во многих случаях оба подхода равно эффективны и информативны. Однако в некоторых отношениях множественный регрессионный анализ обладает преимуществом. Здесь я приведу два аргумента в пользу его использования. 1. Множественный регрессионный анализ особенно удобен в тех случаях, когда независимая переменная является непрерывной величиной, то есть включает широкое множество значений, а не просто несколько дискретных уровней. Пример непрерывной переменной — IQ. Включив в наше исследование IQ, мы получили бы разброс значений около 60-70 пунктов. При использовании ДА учесть всю эту дисперсию невозможно; самое большее, что мы могли бы сделать, это произвести приблизительную классификацию на «высокий», «средний» и «Низкий» интеллект. При использовании же множественного регрессионного анализа нет потери информации, поскольку переменные рассматриваются на континууме и анализируются все фактические показатели. 2. Множественный регрессионный анализ особенно подходит для изучения вопроса, о котором уже говорилось вэтом разделе: определения силы влияния независимой переменной на зависимую. Основным статистическим показателем во множественном регрессионном анализе является R2: доля дисперсии зависимой переменной, объясняемая совокупностью изучаемых независимых переменных. То есть R2 указывает на то, как «действуют» наши предикторы — насколько точно мы можем предсказать изменчивость критерия при помощи выбранной совокупности независимых переменных. Хотя сделать это и нелегко, при помощи регрессионного анализа все же можно оценить вклад каждого из предикторов в дисперсию критерия, как количественное выражение этого вклада, так и тип связи предиктора с критерием. Среди учебников, посвященных множественному регрессионному анализу, можно назвать такие работы, как Cohen & Cohen, 1983; Draper & Smith, 1981; Pedhazur, 1982. В книге Керлингера (Kcrlinger, 1986), на которую мы уже ссылались, можно найти весьма доступное введение в данную проблематику; кроме того, это вел иколенная работа по методологии, с которой стоит ознакомиться любому, кого интересует тема психологического исследования. Общие принципы Завершим эту главу некоторыми общими рекомендациями, касающимися статистической части исследования. Первая рекомендация уже была дана в главе 1: все необходимо планировать. Из всего сказанного в этой главе должно быть ясно, что есть такие аспекты анализа данных, которые нельзя полностью предусмотреть. Исследователь, к примеру, может не знать, каким будет распределение данных, пока не осуществит их сбор. Могут также появляться неожиданные, но интересные результаты, требующие статистической проверки, которую нельзя предусмотреть с самого начала. Однако настолько, насколько это возможно, количество таких статистических операций по уже свершившемуся факту следует свести к минимуму. С самого начала исследователь должен знать основные вопросы, которые будут анализироваться, и конкретные статистические критерии, которые будут использованы при анализе. Планирование помогает избежать несвоевременного разбора данных, с проведением множества проверок в поисках того, что могло бы оказаться значимым. Кроме того, планирование позволяет удостовериться в том, что для анализируемых данных и вопросов есть подходящие статистические процедуры, и выбрать наиболее мощные [1 информативные критерии. Вторая рекомендация — будьте аккуратны. Выводы, которые можно сделать на основе результатов исследования, полностью зависят от точности статистических расчетов. Ошибка при вычислении может привести к ошибке в выводах, иногда принципиальной. Кроме того, вычислительные ошибки обнаружить труднее, чем другие; в исследовательском отчете можно обнаружить методологические просчеты, но результаты математических действий читатель, как правило, принимает на веру. Поэтому крайне важно, чтобы каждая операция проходила тщательную проверку. В идеальном случае, все расчеты должны произвести, по меньшей мере, два независимых специалиста. Полезно также сравнить результаты двух или более методов подсчета (например, на калькуляторе и на компьютере). От исследователя требуется не просто обычная аккуратность; иногда возникают ситуации, когда статистические результаты столь необычны, что их нельзя не перепроверить. В частности, подозрения должны вызывать любые случаи несоответствия дескриптивных показателей и логических выводов о значимости. Дескриптивные и логические показатели основаны на одних и тех же данных, и поэтому они всегда должны определенным образом согласовываться. Установление статистической значимости ничтожной разницы или отсутствие значимости довольно существенной разницы должно быть стимулом к перепроверке расчетов. Есть и еще одно замечание, которое можно сделать о проверке. Исследователь должен избегать дифференцированных проверок, когда результаты, противоречащие ожиданиям, анализируются со всей тщательностью, а результаты, подтверждающие ожидания, не проверяются. Как бы ни было естественным такое поведение, оно позволяет вкрасться эффектам необъективности экспериментатора: результатом исправления только негативных ошибок может быть псевдодоказательство гипотез исследователя. Разумеется, лучше всего проверять и корректировать все. Последняя рекомендация — обращайтесь за советом. Сегодня доступно столько источников — учебники, компьютерные программы, специалисты в области статистики, — что новичку нужно быть совершено безрассудным человеком, чтобы в одиночку пуститься в плавание по коварным водам статистики. К эксперту можно обратиться на любом этапе процесса исследования, начиная с первичного выбора системы измерения и плана и кончая подготовкой к публикации исследовательского отчета. Возможно, имеет смысл несколько более подробно рассмотреть письменные источники. Я уже упоминал лучшие учебники по всему курсу статистики, а также по отдельном его темам. Некоторые статистические вопросы и соответствующие процедуры имеют особое значение в исследованиях в области психологии развития. В этой главе мы не рассматривали статистические процедуры, наиболее часто используемые в психологии развития; этому есть два объяснения: большинство вопросов статистики, с которыми имеет дело исследователь в области психологии развития, в действительности ничем не отличаются от вопросов, с которыми сталкиваются все исследователи-психологи; а те вопросы, которые все же специфичны для психологии развития, настолько сложны, что углубляться в них здесь не имеет смысла. Заметьте, однако, что есть полезные (хотя подчас весьма трудные) работы, посвященные статистическим процедурам, имеющим особое значение именно в психологии развития (см. например: Achenbach, 1978; Applebaum & MacCall, 1983; Collins & Horn, 1991; Nunnally, 1982). Резюме Психологи используют статистические показатели, преследуя две связанные между собой цели. Дескриптивные статистические показатели дают краткую характеристику данным; они представляют собой своего рода первичное описание того, что было обнаружено в исследовании. К ним относят меры центральной тенденции, главной из которых является среднее, и меры изменчивости, главными из которых являются дисперсия и стандартное отклонение. С помощью статистических показателей, выводимых логическим путем, производится не просто описание данных, а определение статистической значимости. Суть вопроса состоит в том, значимо ли отклоняются полученные результаты от того, что могло произойти случайно, при этом случайность является основой нуль-гипотезы об отсутствии различий между сравниваемыми группами. В качестве примера логических критериев рассматривается ?-критерий, который можно использовать для сравнения средних значений в двух группах. Как и у большинства логических критериев, значимость Меритерия зависит от трех факторов: степени различия групп, уровня изменчивости значений в каждой группе и объема выборки. Подчеркивается, что выводы, основанные на использовании логических критериев, всегда носят вероятностный характер; всегда существует возможность допустить ошибку: ошибку первого рода, при которой происходит ошибочное отвержение истинной нуль-гипотезы, и ошибку второго рода, при которой не отвергается ложная нуль-гипотеза. Подчеркивается также, что при проверке статистической значимости исключается возможность объяснения результатов случайной дисперсией,'однако сама статистическая значимость не гарантирует ни валидности исследования, ни научной ценности результатов. Затем рассматриваются виды статистического анализа, которые подходят для разного типа данных, то есть вопрос, как выбрать логический критерий. При выборе критерия следует учитывать три фактора: первый — это уровень измерения — производится измерение по номинальной, порядковой, интервальной шкале или по шкале интервалов. Второй фактор — распределение полученных данных — в частности, распределены ли данные по закону нормального распределения. Так называемые параметрические критерии, например С-критерий и /-"-критерий, зависят от определенных предположений, касающихся распределения данных. Часто они обладают большей мощностью, чем непараметрические критерии, лучше выявляя истинные эффекты. В то же время возможность использования параметрических критериев ограничена рядом условий. Третий фактор — план исследования: сколько включено независимых переменных, сколько уровней имеет каждая переменная, производится внутри- или межсубъектное сравнение. Помимо выявления межгрушювых различий существует еще одна область использования статистических процедур — установление меры связи между переменными. Корреляционные статистические показатели указывают на степень линейной связи между переменными. Статистическая значимость коэффициента корреляции зависит от его величины и объема выборки. Сила связи зависит от величины коэффициента корреляции: чем ближе он к единице, тем больше возможностей предсказать один показатель, зная другой. На коэффициент корреляции влияет диапазон изменения показателей в двух группах; чтобы результаты можно было генерализировать, этот диапазон должен соответствовать диапазону изменения показателей в популяции. Как бы ни был гибок дисперсионный анализ, есть ситуации, когда уместнее использовать другую статистическую процедуру. В исследованиях с четкими гипотезами предпочтительнее использовать плановые сравнения, а не обобщенный ДА. Предварительно спланированные процедуры более эффективны, чем единичные сравнения. Наряду со значимостью исследователя часто интересует сила влияния независимой переменной. Существуют разнообразные меры величины эффекта, простейшая из них — d — разница между двумя средними, разделенная на стандартное отклонение. В исследованиях с двумя и более зависимым переменными возможной альтернативой ДА является мультивариаитный дисперсионный анализ, или МДА. МДА используется в тех случаях, когда зависимые переменные образуют совокупность связанных между собой элементов, при этом МДА дает возможность осуществить более точную проверку эффектов. Наконец, альтернатива ДА — множественный регрессионный анализ, система методов статистического анализа, одним из которых, собственно, и является ДА. Хотя две эти процедуры зачастую взаимозаменяемы, есть ситуации, когда множественный регрессионный анализ предпочтительнее ДА, в частности, когда независимые переменные — непрерывные, а не дискретные величины. Главу завершает изложение нескольких общих замечаний — три рекомендации: составлять предварительный план, производить расчеты аккуратно и при необходимости обращаться к специалистам. Упражнения Исследователь А сравнивает 10 экспериментальные и 10 контрольных испытуемых и выявляет значимое различие между группами на уровне р = 0,04. Исследователь В сравнивает 100 экспериментальных и 100 контрольных испытуемых и выявляет значимое различие между группами на уровне р = 0,04. О каком из этих различий вы бы смогли с большей уверенностью сказать, что это не результат случайности? Какие из результатов отражают более серьезное различие между условиями проведения исследования? Обоснуйте свои выводы. Как вам стало известно из этой главы и как вы увидите в дальнейшем, когда будете читать раздел, посвященный результатам, обозначение статистических показателей несет определенный смысл. Соответственно, анализ кратких обозначений статистических терминов помогает проверить, насколько верно вы понимаете смысл этих терминов и понятий. Объясните как можно более точно, что, по вашему мнению, обозначают понятия, стоящие за представленными ниже обозначениями: р г t N F SD. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Главная | Контакты | Прислать материал | Добавить в избранное | Сообщить об ошибке |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||