|
||||
|
Глава 4 МЕХАНИЗМЫ РАБОТЫ ЯЗЫКА Грамматика за работой Журналисты говорят, что это не новость, когда собака кусает человека; вот когда человек кусает собаку — это что-то новенькое. И именно в этом заключена суть языкового инстинкта: язык сообщает о чем-то новом. Цепочки слов, называемые «предложениями», не просто подстегивают память, напоминая вам о человеке и лучшем друге человека и предлагая додумать остальное; они сообщают вам, кто произвел какое действие и над кем. Таким образом мы, как правило, получаем больше информации из текстов, чем Вуди Аллен[28] — из «Войны и мира», который был прочитан им за два часа после уроков скоростного чтения: «Это было о каких-то русских». Язык, помимо всего прочего, позволяет нам выяснить, как занимаются любовью осьминоги, как вывести вишневые потеки с платья, почему у Тэда было разбито сердце, смогут ли «Ред сокс» выиграть первенство по бейсболу без хорошего игрока на подаче, как смастерить атомную бомбу в собственном подвале и от чего умерла Екатерина Великая. Когда ученые видят какое-то явное проявление чудодейства в природе, например, когда летучие мыши выслеживают насекомых в полной темноте или когда лосось возвращается метать икру в родной реке, они начинают искать стоящий за этим естественнонаучный принцип. В случае с летучими мышами это ультразвук; в случае с лососем — следование тончайшей нити запаха. Какое же чудодейство стоит за способностью Homo sapiens сообщать о том, что человек кусает собаку? В действительности, таких чудодейств не одно, а два, и они ассоциируются с именами двух европейских ученых XIX века. Первый принцип, сформулированный швейцарским лингвистом — Фердинандом де Соссюром, это — «произвольность знака» — полностью условное соответствие звука смыслу. Слово dog ‘собака’ не похоже на собаку, не бегает и не лает, как собака, но тем не менее, означает «собака». Так происходит, поскольку каждый носитель английского языка в детстве прошел одним и тем же путем автоматического запоминания, соединившим звучание со смыслом. Благодаря этому стандартизированному запоминанию члены языкового сообщества получают огромное преимущество: возможность передать мысль из сознания в сознание практически мгновенно. Иногда скоропалительный брак звучания и смысла бывает забавен. Как отмечает Ричард Ледерер в «Безумном английском» («Crazy English»), We drive on a parkway but park in a driveway ‘мы ездим по парковой дороге, но паркуемся на проезжей части’, в гамбургере (hamburger) нет ветчины[29], а в «сладких хлебцах» (sweetbreads) — хлеба[30], голубика (bluberries) действительно синяя (blue), а вот клюква (cranberries) не ходит с клюкой. Но подумайте о «разумной» альтернативе передавать мысли так, чтобы слушатели постигали содержание благодаря форме. Этот вариант так до смешного ненадежен и так напрашивается на остроумное обыгрывание, что мы превратили его в игру, такую как, например, пикшенери[31] или шарады. Второе чудодейство, лежащее в основе языкового инстинкта, заключено в высказывании Вильгельма фон Гумбольдта, который явился предтечей Хомского: язык «бесконечным образом использует конечные средства». Мы видим разницу между забывающейся фразой Собака кусает человека и таким открытием, как Человек кусает собаку благодаря порядку слов, в котором расположены собака, человек и кусает. Таким образом, мы используем некий код для перевода с одного порядка слов — на другой и с одной комбинаций мыслей — на другую. Этот код, или набор правил, называется генеративной (порождающей) грамматикой; как уже упоминалось, не следует путать ее со школьной и стилистической грамматикой, с которыми мы сталкивались в учебных заведениях. Принцип, лежащий в основе грамматики, не обычен для естественной, природной среды. Грамматика — это пример «дискретной комбинаторной системы». Конечное число дискретных элементов (в данном случае — слов) отбирается, соединяется, перемещается для создания больших структур (в данном случае — предложений) со свойствами, совершенно отличными от свойств составляющих их элементов. Например, значение предложения Человек кусает собаку отлично не только от значения каждого из трех слов, его составляющих, но также и от значения тех же слов, составленных в обратном порядке. В дискретной комбинаторной системе, такой как язык, может существовать неограниченное число абсолютно отличных друг от друга комбинаций с неограниченным же диапазоном свойств. Другая замечательная дискретная комбинаторная система в естественной среде — это генетический код в ДНК, где четыре вида нуклеотидов комбинируются в шестьдесят четыре вида кодонов, а кодоны могут составлять ряды неограниченного количества различных генов. Многие биологи делали обобщения на основе тесной параллели между принципами грамматических и генетических комбинаций. На профессиональном языке генетиков о рядах ДНК говорят, что они содержат «буквы» и «пунктуацию», могут быть «палиндромические», «не значимые» или «синонимические», их можно «транскрибировать» и «переводить», и даже «хранить в библиотеках». Иммунолог Нильс Жерн назвал свою нобелевскую лекцию «Генеративная грамматика иммунной системы». Большинство сложных систем, которые мы наблюдаем в мире, напротив, являются контаминирующими системами, как, например, геология, смешение красок, кулинария, звук, свет и погода. В контаминирующей системе свойства комбинации находятся среди свойств ее элементов, а свойства элементов теряются в общей массе соединения. Например, смешение красной и белой краски дает розовую краску. Таким образом, область свойств, которая имеется в контаминирующей системе, очень ограничена, и единственный способ обнаружить различия между большим числом комбинаций — это выделять все более и более тонкие отличия. Может и не быть совпадением тот факт, что две системы во вселенной, наиболее впечатляющие нас неограниченностью своего сложного строения — жизнь и сознание — имеют в основе дискретные комбинаторные системы. Многие биологи уверены, что если бы наследственность не выражалась в дискретных элементах, то эволюция (такая, какова она в нашем понимании) не была бы возможна. Таким образом, принцип работы языка таков, что в мозгу каждого человека содержится набор слов и понятий, которые эти слова выражают (ментальный словарь), а также набор правил, по которым слова сочетаются, чтобы передать отношения между понятиями (ментальная грамматика). Мир слов мы рассмотрим в следующей главе, эта посвящена строению грамматики. Тот факт, что грамматика — это дискретная комбинаторная система, имеет два важных следствия. Первое — это абсолютная бескрайность языка. Пойдите в Библиотеку Конгресса и выберите наугад предложение из любого тома — существует очень большая вероятность того, что вы не сможете найти его точное повторение, как бы долго вы ни искали. При попытке представить, сколько предложений способен продуцировать обычный человек, захватывает дух. Если перебить говорящего в любой случайной точке произносимого предложения, существует в среднем около десяти различных слов, которыми можно было бы продолжить предложение с данного места, так чтобы предложение было грамматически правильным и имело смысл. (В некоторых точках предложения оно может быть продолжено только одним словом, в других — существует выбор из тысяч; десять — среднее значение.) Давайте примем как факт, способность человека продуцировать предложение длиной до двадцати слов. Таким образом количество предложений, которые доступны говорящему, в принципе, может равняться 1020 (единице с двадцатью нулями или ста миллионам триллионов). При скорости пять секунд на предложение человеку понадобилось бы детство в примерно сто триллионов лет (исключая время на еду и сон), чтобы все их запомнить. На самом деле, ограничение в двадцать слов слишком строгое. Следующее вполне доступное пониманию предложение, принадлежащее Бернарду Шоу, содержит 110 слов (в его английском варианте — Перев.):
Действительно, если оставить в стороне тот факт, что нам отпущено около семидесяти лет жизни, каждый из нас способен произнести неограниченное количество различных предложений. Используя ту же логику, которая показывает, что существует неограниченное количество целых чисел (если вы думаете, что знаете самое большое целое число, просто прибавьте к нему единицу, и вы получите другое) должно существовать неограниченное количество предложений. В «Книге рекордов Гиннесса» было заявлено, что самым длинным предложением на английском языке является цепочка протяженностью в 1300 слов из романа Уильяма Фолкнера «Авессалом, Авессалом!», которая начинается так:
Я намерен обрести бессмертие, предоставив следующий побивающий рекорды результат:
Но, вероятно, славы мне хватит лишь на пятнадцать минут, упомянутые в известном высказывании[32], потому что скоро мой результат будет превзойден:
Но и этот рекорд будет побит, как только кто-нибудь предложит следующее:
И так далее до бесконечности. Бесконечное использование конечных средств отличает человеческий мозг практически от всех искусственных механизмов продуцирования речи, с которыми мы встречаемся в повседневности, как то: говорящие куклы, машины, которые просят вас закрывать двери, и жизнерадостные инструкции голосовой почты («Нажмите „ОК“ для дальнейшего выбора»), все из которых используют ограниченный набор заранее составленных предложений. Второе следствие такой организации грамматики — в том, что грамматика является кодом, не зависимым от сознания. Грамматика указывает, как должны сочетаться слова для передачи значений; это указание не зависит от конкретных значений, которые мы обычно передаем или ожидаем получить от других. Благодаря этому все мы чувствуем, что некоторые цепочки слов, которым можно дать осмысленное толкование, не соответствуют грамматическому коду английского языка. Ниже приводятся некоторые цепочки слов, которые мы легко можем истолковать, но которые, как мы чувствуем, неправильно образованы:
Эти предложения «грамматически неправильные» не в том смысле, что это разорванные инфинитивные конструкции[33], обособленные причастные обороты и прочие ужасы, обитающие в классной комнате, но в том смысле, что у любого среднего говорящего на языке подсознательно возникает чувство, что с этими предложениями что-то не так, несмотря на возможность истолкования. Грамматическая неправильность — это просто следствие того, что у нас имеется встроенный код для толкования предложений. Некоторые цепочки слов поддаются пониманию, но у нас отсутствует твердая уверенность, что говорящий использовал для продуцирования этих предложений тот же самый код, что мы используем для их толкования. По той же самой причине компьютеры, менее, чем слушатели, склонные прощать грамматическую некорректность данных при вводе, выражают свое неудовольствие в слишком хорошо всем знакомых диалогах, как то:
Может иметь место и противоположное явление. Предложение может быть бессмысленным, но все же расцениваться как грамматически правильное. Классический пример приведен Хомским[34], это его единственное высказывание, попавшее в «Словарь всем знакомых цитат Барлетта» (Bartlett’s Familiar Quotations):
Это предложение было изобретено для того, чтобы показать, что синтаксис и смысл могут быть независимы друг от друга, но то же самое было доказано задолго до Хомского — на этом построен весь жанр бессмыслицы в поэзии и прозе, популярный в XIX веке. Вот пример из стихотворения Эдварда Лира — признанного мастера бессмыслицы: It’s a fact the whole world knows Марк Твен однажды спародировал романтическое описание природы, сделанное скорее ради сладкозвучия, чем ради содержания:
И почти что каждому знакомо стихотворение из «Алисы в Зазеркалье» Льюиса Кэрролла, которое заканчивается так: Он стал под дерево и ждет, Как сказала Алиса: «Каким-то образом от этого у меня в голове появляются мысли, только я не знаю точно, какие!» И хотя здравый смысл и знание действительности, никак не способствуют пониманию этого отрывка, носители английского языка признают, что он грамматически правилен, а ментальные правила англоговорящих позволяют им вычленить точный, хотя и абстрактный, костяк смысла. Алиса сделала следующее заключение: «Кто-то кого-то здесь убил — по крайней мере это ясно…» А прочитав цитату Хомского в словаре Барлетта любой может ответить на вопросы типа: «Кто спал? Как? Спал кто-то один или их было несколько? Что это были за мысли?» * * *Каковы же могут быть принципы работы комбинаторной грамматики, лежащей в основе механизмов работы человеческого языка? Самый легкодостижимый способ расставлять слова в неком порядке описан в романе Майкла Фрейна «Человек-жестянка». Главный герой по фамилии Голдвассер — инженер, работающий в научно-исследовательском институте проблем автоматизации. Он должен сконструировать компьютерную систему, которая будет выдавать стандартные истории, которые встречаются в ежедневных газетах, типа «Парализованная девушка собирается снова танцевать». В нижеприведенном отрывке он проводит ручное тестирование алгоритма, который будет составлять истории о событиях в королевской семье:
Давайте назовем это «генератор цепочек слов» (технический термин — «модель языка с конечным числом состояний», или «модель Маркова»). Генератор цепочек слов — это комплект из списков слов или заготовок для предложений и набор указаний для следования от списка к списку. Генератор строит предложение, выбирая слово из одного списка, затем — из другого и так далее. (Чтобы узнать сказанное кем-то предложение, нужно просто просмотреть одно за другим слова в каждом списке.) Системы для составления цепочек слов часто используются в сатирах типа упомянутого романа Фрейна, как рецепты типа «сделай сам» для сочинения подобных образцов словоблудия. Например, вот Генератор Общественнонаучного жаргона, которым читатель может воспользоваться следующим образом: выбрать наугад слово из первой колонки, затем — слово из второй, затем — из третьей и выстроить их друг за другом для создания весомо звучащего термина, например: inductive aggregating interdependence ‘индуктивная дополняющая взаимозависимость’.
Недавно я видел генератор цепочек слов, который составляет захватывающие аннотации на книжных обложках, и другой такой прибор, составляющий тексты песен Боба Дилана. Генератор цепочек слов — это простейший образчик дискретной комбинаторной системы, поскольку он способен создать неограниченное количество различных комбинаций из ограниченного количества элементов. Невзирая на пародии, генератор цепочек слов способен составить неограниченное количество наборов грамматически правильных английских предложений. Например, донельзя простая схема  позволяет составить много предложений, таких как: A girl eats ice-cream ‘Какая-то девочка ест мороженое’ или The happy dog eats candy ‘Эта радостная собака ест конфеты’. Эта схема позволяет составить неограниченное количество предложений благодаря петле наверху, которая может направить генератор от списка, представленного словом happy ‘радостный’, снова к этому же списку любое количество раз: The happy dog eats ice-cream ‘Эта радостная собака ест мороженое’, The happy happy dog eats ice-cream ‘Эта радостная радостная собака ест мороженое’, и т.д. Когда инженеру требуется придумать систему для сочетания слов в определенном порядке, генератор цепочек слов — это первое решение, которое приходит в голову. Запись голоса, сообщающего вам телефонный номер, когда вы звоните в справочную — хороший тому пример. Там имеется запись произнесенных человеком десяти цифр, каждая из которых записана в семи различных интонационных моделях (одна соответствует первой цифре номера, одна — второй и т.д.). Имея всего семьдесят этих записей можно составить десять миллионов телефонных номеров; имея еще тридцать записей для трехзначных кодов областей, возможно составление десяти миллиардов номеров (на практике многие из них никогда не используются из-за налагаемых ограничений, например — на присутствие 0 или 1 в начале телефонного номера). В действительности, были сделаны серьезные попытки представить английский язык как одну большую цепочку слов. Чтобы сделать это по возможности реалистичным, переходы от одного списка слов к другому должны отражать действительную вероятность того, что такие типы слов могут следовать друг за другом в английском языке (например, существует бо?льшая вероятность того, что за словом that ‘это’ последует is ‘есть’, а не indicates ‘указывает’). Были составлены колоссальные базы данных этих «вероятностей последующего слова»; это делалось путем компьютерного анализа корпуса текстов на английском языке или опроса добровольцев, которым предлагалось назвать первые слова, пришедшие в голову после того, как они услышат данное слово или ряды слов. Некоторые психологи предполагали, что человеческий язык основан на громадной цепи слов, хранящейся в мозгу. Эта идея созвучна теориям реакции на раздражение: некое раздражение вызывает в качестве реакции произносимое слово, затем говорящий получает вызванную им самим реакцию, которая служит как дальнейший раздражитель, вызывая одно из нескольких слов в качестве очередной реакции и т.д. Но вызывает подозрения тот факт, что генератор цепочки слов кажется прямо-таки созданным для пародирования, как, например, в романе Фрейна. Суть этих разнообразных пародий в том, что литературный жанр, являющийся объектом иронии, настолько бессмыслен и заезжен, что простой механический метод позволяет наплодить неограниченное количество образчиков этого жанра, которые почти без натяжки могут сойти за истинное произведение. Юмор заключается в следующем несоответствии: по всеобщему признанию, люди (даже социологи и журналисты) не могут на самом деле быть генераторами цепочек слов; они только кажутся таковыми. Современные грамматические исследования начались тогда, когда Хомский продемонстрировал, что генераторы цепочек слов не просто слегка подозрительны; принцип их работы в корне отличен от принципа работы человеческого языка. Они являются дискретными комбинаторными системами, но не того типа. Возникают три проблемы, каждая из которых освещает один из реальных аспектов работы языка. Во-первых, предложение на английском языке полностью отличается от цепочки слов, соединенных вместе в соответствии с вероятностью последующего слова, характерной для английского языка. Вспомните предложение Хомского: Бесцветные зеленые мысли спят яростно. Он сочинил его, чтобы показать, что грамматически правильной может быть не только бессмыслица, но и невероятная последовательность слов. Вероятность того, что в английском тексте за словом бесцветные последует слово зеленые, естественно, равна нулю. Нулевой является и вероятность того, что за словом зеленые последует слово мысли, за словом мысли — спать, а за спать — яростно. Тем не менее, данная цепочка слов — это правильно построенное английское предложение. В противоположность этому, если действительно составлять цепочки слов, пользуясь таблицами вероятности последующего слова, получающиеся в итоге цепочки слов далеки от того, чтобы называться правильно построенными предложениями. Например, вы подбираете ряд слов, которые с наибольшей вероятностью могут последовать за каждой последовательностью из четырех слов, и используете эти подборки, чтобы слово за словом нарастить цепочку слов. При этом вы всегда смотрите на последние четыре слова, чтобы они определили следующее. Цепочка получится извращенно «английсковатой», но не английской, например: House to ask for is to earn our living by working towards a goal for his team in old New-York was a wonderful place wasn’t it even pleasant to talk about and laugh hard when he tells lies he should not tell me the reason why you are is evident ‘Дом для сдачи внаем должен зарабатывать нам на жизнь, работая над задачей, требующей коллективного решения в старом Нью-Йорке, был чудесным местом, не так ли, даже приятным для обсуждения и громкого смеха, когда он лжет, он не должен говорить мне причину, почему ты являешься очевидным’. Несоответствие между английскими предложениями и цепочками слов на английском заставляет прийти к двум выводам. Когда люди усваивают язык, они усваивают его, запоминая не то, какое слово должно следовать за каким. Они усваивают его, запоминая, какая часть речи — существительное, глагол и т.д. следует за какой. Таким образом, мы можем признать бесцветные зеленые мысли, поскольку там точно такой же порядок существительных и прилагательных, который мы усвоили на примере более привычных предложений, например, strapless black dresses ‘декольтированные черные платья’. Второй вывод будет о том, что существительные, глаголы и прилагательные не просто механически соединены в одну длинную цепочку; для предложений существует некая всеобъемлющая схема, или план, согласно которому каждое слово занимает определенное гнездо. Если генератор цепочек слов достаточно умно сконструирован, он может справиться с этими проблемами. Но Хомский изначально отвергал саму идею о том, что человеческий язык является цепочкой слов. Он доказал, что некоторые типы английских предложений даже в принципе не могут быть составлены генератором цепочек слов, каким бы большим он ни был, и как точно бы он ни соответствовал таблицам вероятности. Рассмотрим следующие предложения:
На первый взгляд кажется, что уместить эти предложения в схему просто: 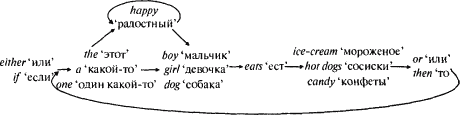 Но этот генератор не работает. За either ‘или’ дальше в предложении должно последовать or ‘или’; никто не говорит: Either the girl eats ice-cream, then the girl likes candy ‘Или эта девочка ест мороженое, то эта девочка любит конфеты’. Аналогично, if ‘если’ требует then ‘то’; никто не говорит: If the girl eats ice-cream, or the girl likes candy ‘Если эта девочка ест мороженое, или эта девочка любит конфеты’. Но чтобы удовлетворить потребность слова, стоящего в начале предложения, в каком-то другом слове, стоящем в конце предложения, генератор должен помнить слово, стоящее в начале, все то время, что он продуцирует все слова, расположенные между началом и концом. В этом-то и состоит проблема: генератор цепочек слов подвержен амнезии, запоминая только то, из какого списка он выбрал самое последнее слово, и не помня ничего, что этому предшествовало. К тому моменту, как он достигает списка or ‘или’ / then ‘то’, он не может вспомнить, что было сказано в начале: either ‘или’ либо if ‘если’. Имея счастливую возможность оглядеть весь пройденный путь с высоты, мы можем вспомнить, какой выбор сделал генератор на первой развилке, но сам генератор, перебегая, как муравей, от списка к списку, запоминать не способен. Тут можно подумать, что было бы просто переделать генератор таким образом, чтобы в конце предложения ему не приходилось вспоминать, какой выбор был сделан в начале. Например, можно было бы соединить either ‘или’ с or ‘или’, а также — со всеми возможными последовательностями слов между ними в одну огромную последовательность, а if ‘если’ соединить с then ‘то’ и со всеми возможными последовательностями слов между ними в другую огромную последовательность. Потом можно было бы обратиться к третьему варианту последовательности, растягивая цепь настолько, что я вынужден поместить ее отдельно. Но кое-что в этом решении вызывает немедленное отторжение: получаются три идентичные подсистемы. Разумеется, то, что люди могут сказать между either и or, они могут сказать и между if и then, а также после or или then. Но эта возможность должна естественным образом проистекать из строения некого генератора в голове у человека, позволяющего ему говорить. Она не должна зависеть от того, станет ли конструктор генератора тщательно расписывать три идентичных набора инструкций (или, что ближе к реальности, придется ли ребенку, изучать структуру английского предложения, трижды: между if и then, между either и or, а также — после then и or). 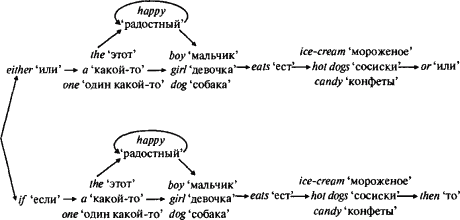 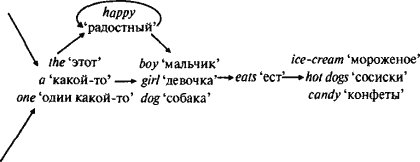 Но Хомский продемонстрировал, что проблема лежит даже еще глубже. Каждое из данных предложений можно включить в состав любого другого, включая их самих:
В случае с первым предложением генератору нужно запомнить if ‘если’ и either ‘или’ так, чтобы потом их можно было продолжить словами or ‘или’ и then ‘то’, именно в такой последовательности. В случае со вторым предложением ему нужно запомнить either ‘или’ и if ‘если’ так, чтобы потом можно было продолжить предложение словами then ‘то’ и or ‘или’. И так далее. Поскольку в принципе не существует предела количеству if и either, с которых может начинаться предложение и каждому из которых требуется свой собственный порядок then и or, чтобы быть законченным, не выйдет ничего хорошего из раскладывания каждой последовательности в памяти на свои собственные цепочки списков — получится неограниченное количество цепочек, которые не поместятся в обладающем конечными ресурсами мозгу. Этот аргумент может показаться вам слишком схоластическим. Ни один реально живущий человек никогда не начнет предложение со слов: Either either if either if if ‘Или или если или если если’, поэтому имеет ли значение то, что идеальная модель этого человека может продолжить данное предложение словами: then ‘то’… then ‘то’… or ‘или’… then ‘то’… or ‘или’… or ‘или’. Но Хомский просто действовал в русле математической эстетики, используя взаимодействие между either ‘или’ — or ‘или’ и if ‘если’ — then ‘то’ как простейший возможный пример одного из свойств языка — использовать «удаленные зависимости» между словами, появившимися в предложении ранее и позднее — чтобы на математическом уровне доказать, что генератор цепочек слов не способен работать с этими зависимостями. На самом деле, языки изобилуют такими зависимостями, и простые смертные употребляют их постоянно при значительном расстоянии между словами, часто применяя несколько зависимостей одновременно — делая именно то, на что не способен генератор цепочек слов. Например, между грамматистами ходит старая байка о том, что предложение может заканчиваться пятью предлогами. Папаша тащится наверх в комнату сыночка, чтобы почитать ему сказку на ночь. Сыночек замечает, что у папаши за книга, и негодующе кричит: Daddy, what did you bring that book that I don’t want to be read to out of up for? ‘Папа, зачем ты принес наверх эту книгу, из которой я не хочу, чтобы мне читали?’ К моменту произнесения слова read ‘читали’, сыночек должен был задаться целью сохранить в памяти четыре зависимости: to be read ‘читали’ требует to (предлог, обозначающий направленность действия — читали кому), that book that ‘эту книгу, из которой…’ требует предлогов out of, bring ‘принес сюда’ требует up ‘наверх’, a what требует for (словосочетание what for означает ‘зачем’). Другой, еще лучший пример взят из реальной жизни (из письма в журнал «ТВ-гайд»[37]):
В том месте предложения, которое начинается сразу после слова not, автор письма должен был держать в памяти четыре грамматически обязательных положения: 1) not требует -ing (her anger at not receiving acclaim ‘гнев, вызванный неполучением’) требует распространения в виде причастного оборота — гнев, вызванный; 2) at требует существительного или герундия (her anger at not receiving acclaim); 3) подлежащее в единственном числе Pam Dawber’s anger требует, чтобы глагол, стоящий четырнадцатью словами дальше, согласовывался с подлежащим в числе (Dawber’s anger… derives from ‘гнев Пэм Добер… происходит от’); 4) подлежащее в единственном числе, начинающееся с How требует от глагола, стоящего от него через двадцать семь слов согласования в числе (How… escapes me ‘То, как… остается мне непонятным’). Подобно автору, читатель должен держать все эти зависимости в памяти для того, чтобы понять предложение. Теперь, говоря технически, можно было бы соорудить модель цепочки слов, которая могла бы работать даже с такими предложениями, поскольку существует какой-то реальный лимит числа зависимостей, которые говорящему нужно держать в памяти (например, четыре). Но уровень избыточности в генераторе будет абсурдным: для каждой из тысяч комбинаций зависимостей в генераторе придется дублировать идентичную цепочку. Пытаясь поместить в памяти такую суперцепочку, можно легко сойти с ума. * * *Разница между искусственной комбинаторной системой, которую мы рассматриваем на примере генератора цепочек слов, и естественной системой, которую мы рассматриваем на примере человеческого мозга, обобщена в строке стихотворения Джойса Килмера: «Только Бог может создать дерево»[38]. Предложение — это дерево, а не цепочка. В грамматике человеческого языка слова сгруппированы в синтаксические группы, подобно веточкам присоединенным к ветви. Синтаксической группе присвоено имя — ментальный символ — и маленькие синтаксические группы могут быть объединены в бо?льшие. Возьмем предложение: The happy boy eats ice-cream ‘Этот радостный мальчик ест мороженое’. Оно начинается двумя словами, выступающими вместе как единое целое — это именная группа the happy boy ‘этот радостный мальчик’. В английском именная группа (NP) состоит из имени существительного (N), которому иногда предшествует артикль или «детерминатор» (сокращенно: «det») и любое количество адъективных слов (А). Все это можно обобщить в правиле, которое определяет как выглядят английские именные группы вообще. В стандартном лингвистическом обозначении стрелка означает: «состоит из», скобки означают: «присутствующий факультативно», а звездочка обозначает: «любое желаемое количество этих элементов», но я привожу это правило только для того, чтобы показать, что вся заключенная в нем информация может быть ясно выражена в нескольких символах; можно не обращать внимание на обозначения, а смотреть только на перевод, обычными словами приведенный ниже:
«Именная группа состоит из присутствующего факультативно детерминатора, за которым следует любое количество адъективных слов, за которыми следует существительное». Это правило определяет строение перевернутой вверх ногами ветви дерева: 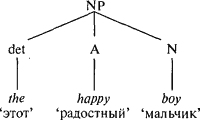 А вот — два других правила, одно из которых дает определение английскому предложению (S), а другое дает определение предикативной или глагольной группе (VP), оба они используют как составную часть символ NP:
Теперь нам потребуется ментальный словарь, который бы уточнил, какое слово принадлежит к какой части речи (имя существительное, глагол, прилагательное, предлог, детерминатор):
Набор правил, подобных тем, которые я привел — «грамматика непосредственно составляющих» — задает предложение, нагружая словами ветви на растущем сверху вниз дереве: 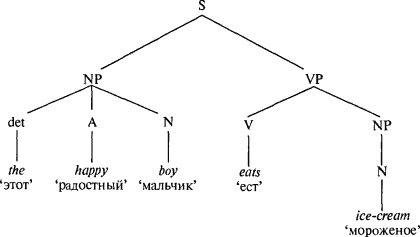 Та невидимая сверхструктура, что удерживает слова на месте, — это могущественное изобретение, устраняющее проблемы, которые были у генераторов цепочек слов. Основная суть древесного представления в том, что дерево модулярно, как и гнездо телефонного коммутатора, или муфта садового шланга. Символ типа «NP» подобен разъему или креплению определенной формы. Он позволяет одному компоненту (синтаксической группе) заскочить в любую из нескольких позиций внутри других компонентов (бо?льших синтаксических групп). Как только тип синтаксической группы задан правилом и ему присвоен свой символ-соединитель, ему никогда более не нужно быть определенным снова, синтаксическая группа может быть подключена в любом месте, где есть соответствующая розетка. Например, в той маленькой грамматике, которую я продемонстрировал, символ «NP» используется и как подлежащее в предложении (S —> NP VP), и как дополнение в глагольной группе (VP —> V NP). В более приближенной к жизни грамматике он также будет использоваться как объект, на который направлено действие предлога near the boy ‘рядом с мальчиком’, в конструкции со значением принадлежности the boy’s hat ‘шапка радостного мальчика’, как косвенное дополнение give the boy a cookie ‘дай печенье мальчику’ и в нескольких других позициях. Такая организация вида «вилка-розетка» объясняет, как люди могут использовать одну и ту же синтаксическую группу во многих разных позициях в предложении, включая:
Нет необходимости выучивать, что прилагательное скорее предшествует существительному (чем наоборот) в позиции подлежащего, затем выучивать то же самое для позиции прямого дополнения, косвенного дополнения и наконец — для позиции обладателя. Заметьте также, что возможность разнородного соединения любой синтаксической группы с любым гнездом делает грамматику независимой от того, что подсказывает нам здравый смысл, задаваемый значениями слов. Этим объясняется, почему мы можем писать и признавать грамматически правильную бессмыслицу. Наша маленькая грамматика допускает существование всех видов бесцветных зеленых предложений, как например: The happy happy candy likes the tall ice-cream ‘Эти радостные-радостные конфеты любят это высокое мороженое’, одновременно сообщая такие неизвестные доселе факты, как: The girl bites the dog ‘Эта девочка кусает эту собаку’. Любопытнее всего, что ветви синтаксического дерева с метками действуют в роли всеобъемлющей памяти или плана для всего предложения. Это позволяет без затруднений справляться с находящимися в гнездах удаленными зависимостями типа: if… then ‘если… то’ и either… or ‘или… или’. Все, что при этом требуется — это правило, которое задает синтаксическую группу, содержащую копию точно такого же вида синтаксической группы, например:
Эти правила включают один представитель некоторого символа внутрь другого представителя того же самого символа (в данном случае — предложение внутрь предложения); это удобный способ (называющийся в логике «рекурсией») создавать бесконечное количество структур. Части большего предложения упорядоченно соединены вместе как группа ветвей, произрастающих из одного узла. Этот узел удерживает вместе каждое if ‘если’ с каждым его then ‘то’ и каждое either ‘или’ с его or ‘или’, как на следующей диаграмме (треугольники использованы как сокращения для большого количества мелких веточек, которые только усложнили бы дело, если бы мы показали их все): 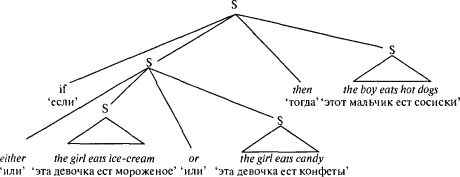 Есть еще один повод поверить в то, что предложение удерживается вместе с помощью ментального дерева. До сих пор я говорил о соединении слов в грамматически правильном порядке вне зависимости от их значения. Но объединение слов в синтаксические группы также необходимо для того, чтобы связать грамматически правильные предложения с их истинным значением — блоками мыслекода. Мы знаем, что приведенное выше предложение рассказывает о девочке, а не о мальчике, который ест мороженое, и о мальчике, а не о девочке, которая ест сосиски; и мы знаем, что еда мальчика является зависимой от того, что ест девочка, а не наоборот. Это происходит потому, что слова девочка и мороженое связаны внутри своей собственной группы аналогично тому, как связаны мальчик и сосиски и два предложения, в которых речь идет о девочке. Для генератора цепочек слов это просто одно несчастное слово, идущее после другого, но для грамматики непосредственно составляющих то, как слова соединены в дереве, отражает соотношение мыслей в мыслекоде. Таким образом, структура составляющих — это одно из решений технической проблемы: как взять взаимосвязанную паутину мыслей в сознании и закодировать их в виде цепочки слов, которые нужно произносить губами одно за другим. Один из способов увидеть, как невидимая структура составляющих определяет значение — это вспомнить одну из упомянутых в главе 3 причин отличия языка от мысли: один определенный отрезок речи может соответствовать двум различным мыслям. Я приводил вам примеры типа Child’s stool is great for use in garden ‘Детский стул — отличная штука для сада’, где одно единственное слово stool ‘стул’ имеет два значения, соответствующие двум словарным статьям ментального словаря. Но иногда целое предложение имеет два значения, даже если каждое слово в отдельности однозначно. В фильме «Звередробилки» герой по имени Гручо Маркс говорит: «Однажды я застрелил слона в моей пижаме. Я так и не узнаю, как он натянул мою пижаму». Вот несколько подобных двусмысленностей, которые время от времени появляются в газетах:
Два значения каждого предложения происходят от двух различных способов, которыми слова могут быть соединены на дереве. Например в синтаксической группе discuss sex with Dick Cavett ‘обсуждать секс с Диком Кэветом’ автор расположил слова в соответствии с левым деревом («РР» означает предложная группа): секс — это то, что подлежит обсуждению, и подлежит обсуждению с Диком Кэветом. 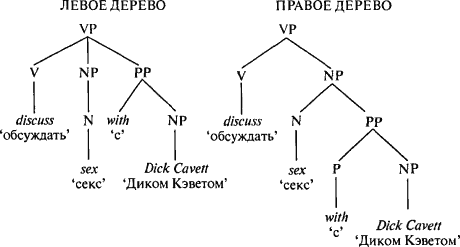 Мы можем вывести альтернативное значение, анализируя слова в соответствии с правым деревом — слова sex with Dick Cavett ‘секс с Диком Кэветом’ образуют на дереве отдельную ветвь, и секс с Диком Кэветом — это то, что подлежит обсуждению. * * *Очевидно, что структура непосредственно составляющих — это материал, из которого сделан язык. Но то, что я продемонстрировал вам — это просто игрушки. Далее в этой главе я постараюсь объяснить современную теорию Хомского о функционировании языка. Работы Хомского являются «классическими» в том смысле, в котором употреблял это слово Марк Твен: то, о чем всем хотелось бы иметь представление, уже прочитав, но что никому не хочется читать. Когда я сталкиваюсь с одной из бесчисленных популярных книг о мышлении, языке и человеческой природе, которые ссылаются на «глубинные структуры значения у Хомского, общие для всех человеческих языков» (что, как мы увидим, ложно по двум причинам), я знаю, что книги Хомского, написанные на протяжении последних двадцати пяти лет покоятся в кабинете автора на верхней полке с неразрезанными страницами и в неистрепанном переплете. Многие из кожи вон лезут, рассуждая о сознании, но когда дело доходит до освоения подробностей работы языка, эти люди проявляют то же нетерпение, что Элиза Дулитл продемонстрировала Генри Хиггинсу в «Пигмалионе», когда она жаловалась: «Я не хочу говорить по правилам. Я хочу говорить, как леди из цветочного магазина». Неспециалисты реагируют еще более резко. У Шекспира во второй части «Короля Генриха VI» мятежник Дик Мясник произносит знаменитую фразу: «Первым делом мы перебьем всех законников». Менее известно второе предложение Дика: обезглавить лорда Сэя. За что? Вот обвинение, выдвинутое вожаком черни Джеком Кедом:
И кто может обвинять этого грамматикофоба, если типичный отрывок из одной узко-специальной работы Хомского звучит так:
Все это — просто беда. Люди, особенно те, кто со знанием дела распространяется о природе сознания, должны проявлять элементарное любопытство, что это за код используют человеческие особи для общения с себе подобными. В свою очередь ученые, зарабатывающие на жизнь изучением языка, должны постараться, чтобы это любопытство было удовлетворено. Но ни тем, ни другим не нужно относиться к теории Хомского как к набору кабалистических заклинаний, которые дозволено бормотать только посвященным. Эта теория — ряд открытий о строении языка, и ее можно оценить интуитивно, если сначала понять проблемы, решения которых она предлагает. В действительности, постижение грамматической теории приносит такое огромное интеллектуальное удовольствие, которое является редкостью для общественных наук. Когда в конце 60-х годов я перешел в старшие классы школы, где была возможность выбирать учебные дисциплины, исходя из их «прикладного» значения, популярность латыни резко пошла на спад (должен признаться, это произошло благодаря таким ученикам, как я). Наша преподавательница латыни миссис Рилли, чьи дифирамбы Риму не смогли замедлить упадок интереса, пыталась убедить нас, что латинская грамматика производит огранку ума, требуя от него точности, логики и постоянства. (В наше время такие аргументы скорее можно услышать от учителя информатики.) Миссис Рилли была права, но латинские парадигмы склонения — это не лучший способ передать природную красоту грамматики. Откровения Универсальной Грамматики гораздо интереснее не только своей обобщенностью и элегантностью, но и тем, что они прикасаются скорее к живым умам, а не к мертвым языкам. * * *Давайте начнем с существительных и глаголов. Ваша учительница грамматики наверняка заставляла вас учить некую формулу, которая соотносила бы части речи с видами значения, как например: A NOUN’s the name of any thing; Но, как это чаще всего бывает при обсуждении проблем языка, учительница была не совсем точна. Верно то, что большинство названий лиц, мест и вещей — существительные, но не верно то, что большинство существительных — это названия лиц, мест или вещей. Существительные обладают любыми значениями:
Точно так же, хотя слова, обозначающие действие, такие как count ‘считать’ и jump ‘прыгать’, обычно являются глаголами, глаголы могут обозначать и что-то другое, например ментальное состояние (know ‘знать’, like ‘любить’), обладание (own ‘владеть, обладать’, have ‘иметь’) и абстрактные отношения между понятиями (falsify ‘фальсифицировать’, prove ‘доказать’). Напротив, одно единственное понятие, такое как being interested ‘быть заинтересованным’, может быть выражено разными частями речи:
Таким образом, часть речи не является видом значения, она является своего рода «фигурой», которая подчиняется определенным правилам, как фигуры в шахматах или фишки в покере. Например, существительное — это просто слово, которое делает что-то свойственное существительным — это вид слов, которые стоят после артикля, к такому слову можно «приклеить» апостроф с буквой s (’s), и так далее. Существует связь между понятиями и категориями частей речи, но эта связь тонка и абстрактна. Когда мы рассматриваем какой-то аспект бытия как нечто, что может быть определено и пересчитано или измерено и что может играть роль в происходящих событиях, язык часто позволяет нам выразить этот аспект существительным, независимо от того является он физическим объектом или нет. Например, когда мы говорим I have three reasons for leaving ‘У меня есть три повода уйти’, мы пересчитываем поводы, как если бы они были объектами (хотя, конечно, мы не думаем буквально, что повод может сидеть на столе или что его можно пнуть ногой так, что он отлетит в другой конец комнаты). Подобно этому, когда мы рассматриваем какой-то аспект бытия как событие или состояние, вовлекающее нескольких участников, которые воздействуют друг на друга, язык часто позволяет нам выразить этот аспект глаголом. Например, когда мы говорим The situation justified drastic measures ‘Ситуация оправдывала жесткие меры’, мы говорим об оправдании как о чем-то, что будто бы сделала ситуация, хотя мы знаем, что оправдание (в этом смысле) нельзя увидеть происходящим в определенное время в определенном месте. Существительные часто используются как названия вещей, а глаголы — как обозначения действий, но поскольку человеческий разум может рассматривать действительность под разным углом, существительные и глаголы не ограничиваются этими сферами употребления. * * *А как быть с синтаксическими группами, которые объединяют слова в ветви дерева? Одно из самых интригующих открытий современной лингвистики состоит в том, что, похоже, у всех синтаксических групп во всех языках мира одинаковое строение. Возьмем именную группу английского языка. Именная группа (NP) названа так благодаря одному особому слову — имени существительному — которое должно находиться в ее составе. Именная группа обязана большинством своих свойств этому одному существительному. Например, именная группа the cat in the hat ‘кошка в шляпе’ относится к определенной кошке, а не к определенной шляпе; значение слова cat ‘кошка’ — центральное для всей группы. Точно так же, группа fox in socks ‘лиса в носках’ относится к лисе, а не к носкам, а вся группа в целом стоит в единственном числе (то есть, мы говорим, что лиса в носках есть или была здесь, а не суть или были здесь), поскольку слово fox ‘лиса’ стоит в единственном числе. Это особое существительное называется «вершиной» синтаксической группы, а информация, оставляемая этим словом и памяти, «распространяется» до наивысшего узла, где она воспринимается как характеризующая синтаксическую группу в целом. То же самое относится к глагольным группам: flying to Rio before the police catch him букв. ‘улететь в Рио, пока полиция не схватила его’ — пример того, как можно улететь, а не того, как может схватить полиция, поэтому flying называется вершиной. И вот он, первый принцип того, как значение синтаксической группы выводится из значений слов, ее составляющих: вся синтаксическая группа «будет о том», о чем будет ее вершина. Второй принцип позволяет синтаксическим группам относиться не только к единичным предметам или действиям, но и к нескольким участникам действия, которые взаимодействуют друг с другом определенным образом, и каждый имеет при этом свою особую роль. Например, предложение Sergey gave the documents to the spy ‘Сергей передал документы шпиону’ говорит не просто о каком-то старом, как мир, акте передачи, оно выстраивает три сущности: Сергея (передающего), документы (передаваемое) и шпиона (получателя). Эти ролевые исполнители (role-players) обычно называются «аргументами» (arguments), или переменными, что не имеет ничего общего с непостоянством, это термин, используемый в логике и математике для обозначения участника отношений. Именная группа также может отводить роли одному или более исполнителям, каждый из которых отвечает за одну роль, как, например, в группе: picture of John, governor of California ‘портрет Джона, губернатора Калифорнии’ и sex with Dick Cavett ‘секс с Диком Кэветом’. Вершина и ролевые исполнители (исполняющие роли, отличные от роли подлежащего, которая является особой) соединены в подгруппе, меньшей, чем именная или глагольная, и снабженной неудобным для запоминания ярлычком, который сделал генеративную лингвистику такой неприглядной: «N-штрих» и «V-штрих», названные так из-за своего написания — N? и V?. 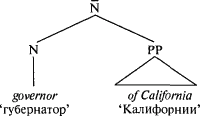 Третья составная часть синтаксической группы — это один или более модификаторов (обычно называемых «адъюнктами»). Модификатор отличается от ролевого исполнителя. Возьмем синтаксическую группу the man from Illinois ‘человек из Иллинойса’. Быть человеком из Иллинойса — это не то же самое, что быть губернатором Калифорнии. Чтобы быть губернатором, вы должны быть губернатором чего-либо; для того, кто является губернатором Калифорнии имеет значение «калифорнийство». И напротив, from Illinois ‘из Иллинойса’ — это просто небольшой кусочек информации, который мы добавляем, чтобы легче было определить, о каком человеке идет речь; происхождение из того или иного штата — это не неотъемлемая часть понятия «человек». Различия в значении между ролевыми исполнителями и модификаторами («аргументами» и «адъюнктами» — на профессиональном жаргоне) и определяют конфигурацию синтаксического дерева. Ролевой исполнитель стоит рядом с вершинным существительным, но модификатор поднимается выше, хотя он все еще продолжает находиться в составе NP. 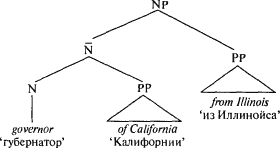 Такое ограничение конфигурации синтаксического дерева — это не просто игра с условными обозначениями — это гипотеза о том, как языковые правила представлены в нашем сознании и управляют нашей речью. Ею обусловлено то, что если синтаксическая группа содержит как ролевого исполнителя, так и модификатор, то ролевой исполнитель должен находиться ближе к вершине, чем модификатор, и модификатор ни при каких обстоятельствах не может занять место между именной вершиной и ролевым исполнителем, не вызывая скрещения ветвей на дереве (например, путем внедрения посторонних слов между составными частями N?), что является запрещенным приемом. Возьмем, к примеру, Рональда Рейгана. Он был губернатором Калифорнии, но являлся уроженцем Тампико, штат Иллинойс. Когда он исполнял должностные функции, о нем можно было бы говорить как о the governor of California from Illinois ‘губернаторе Калифорнии из Иллинойса’ (ролевой исполнитель, затем — модификатор). Было бы странно сказать о нем, как о the governor from Illinois of California ‘губернаторе из Иллинойса Калифорнии’ (модификатор, затем — ролевой исполнитель). Еще показательнее случай с Робертом Ф. Кеннеди: в 1964 г. его сенаторские амбиции столкнулись с тем неприятным фактом, что оба кресла от Массачусетса уже были заняты (одно из них — его младшим братом Эдвардом). Поэтому он просто поселился в штате Нью-Йорк и оттуда баллотировался в сенат Соединенных Штатов, вскоре став the senator from New York from Massachusetts ‘сенатором от штата Нью-Йорк из Массачусетса’. Заметим — не the senator from Massachusetts from New York ‘сенатором от штата Массачусетс из Нью-Йорка’, хотя это больше походило бы на шутку, которую любили рассказывать в свое время жители штата Массачусетс: их штат был единственным, давшим полномочия трем сенаторам. Занятно то, что положения, верные для N? и именных групп, верны также для V? и глагольных групп. Предположим, Сергей передал упомянутые документы шпиону в гостинице. Синтаксическая группа to the spy ‘шпиону’ — это один из ролевых исполнителей при глаголе give ‘передавать’, поскольку не существует акта передачи без получателя. Поэтому слова to the spy разместились вместе с глаголом-вершиной внутри V?. Но группа in the hotel ‘в гостинице’ — это модификатор, комментарий, отсроченное соображение, поэтому оно размещается вне V?, но внутри VP. Таким образом, синтаксические группы выстраиваются согласно своим свойствам: мы можем сказать gave the documents to the spy in a hotel передал документы шпиону в гостинице, но не gave in a hotel the documents to the spy передал документы в гостинице шпиону. Когда вершина сопровождается только одной синтаксической группой, последняя может быть либо ролевым исполнителем (внутри V?), либо модификатором (вне V?, но внутри VP), и фактический порядок слов остается тем же. Рассмотрим следующий отрывок из газетной статьи:
Женщина, находящаяся в расстроенных чувствах, имела в виду модификатор, когда говорила between two parked cars ‘между двумя машинами’, но извращенный ум читателей истолковал это как ролевого исполнителя. Четвертый и последний компонент синтаксической группы — это особая позиция, отведенная для подлежащих (лингвисты называют ее SPEC — произносится «спек» — сокращенное от «спецификатор», а почему так произносится, не спрашивайте). Подлежащее — это особый ролевой исполнитель, обычно — каузальный агенс, если таковой имеется. Например в глагольной группе the guitarists destroy the hotel room ‘гитаристы разрушают гостиничный номер’, именная группа the guitarists — это подлежащее; это каузальный агенс в случае с разрушаемым номером. В действительности, именные группы тоже могут иметь подлежащие, как например, в параллельной NP the guitarists’ destruction of the hotel room букв. ‘разрушение гитаристами гостиничного номера’. Вот полная анатомия VP и NP: 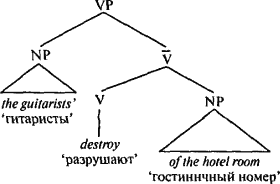 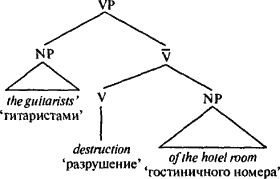 И тут начинается самое интересное. Вы должны были уже заметить, что у именных и глагольных групп много общего: 1) вершина, которая дает группе ее название и определяет содержание, 2) несколько ролевых исполнителей, которые расположены вместе с вершиной внутри под-группы (N? или V?), 3) модификаторы, которые появляются вне N или V? и 4) подлежащее. Внутренний порядок в именной или глагольной группе одинаков — имя существительное идет перед своими ролевыми исполнителями: the destruction of the hotel room ‘разрушение гостиничного номера’, а не the of the hotel room destruction ‘гостиничного номера разрушение’, и так же перед своими ролевыми исполнителями идет глагол to destroy the hotel room ‘разрушать гостиничный номер’, а не to the hotel room destroy ‘гостиничный номер разрушать’. Модификаторы в обоих случаях отходят вправо, подлежащее — влево. Кажется, что у двух синтаксических групп стандартная схема. В действительности, та же схема взаиморасположения возникает там, где только возможно. Возьмем, например, предложную группу (РР) in the hotel ‘в гостинице’. У нее есть вершина — предлог in ‘в’, обозначающий что-то вроде «внутреннее пространство», и идущую после него роль — тот предмет, внутреннее пространство которого выбрано, в данном случае — гостиница. То же самое верно и для адъективной группы (АР): в высказывании afraid of the wolf ‘боящийся волка’, вершина — адъектив afraid ‘боящийся’ идет перед своим ролевым исполнителем — источником страха. Зная об этом общем строении, уже не нужно выписывать длинный список правил, чтобы осознать, что же происходит в голове у говорящего. Возможно, существует только пара сверхправил для всего языка, в которых различия между существительными, глаголами, предлогами и прилагательными сведены на нет, и все они вместе обозначены переменной типа «X». Поскольку синтаксическая группа просто наследует свойства своей вершины (a tall man ‘высокий человек’ — это некий man ‘человек’), излишне называть синтаксическую группу с ведущим словом существительным — «именной группой», мы могли бы назвать ее просто «X-группой», поскольку свойства существительного — ведущего слова, как например, принадлежность к миру людей, а также вся другая информация, содержащаяся в ведущем слове, распространяется на характеристику синтаксической группы в целом. Вот как выглядит это сверхправило (как и прежде, сосредоточьтесь на формулировке, а не на схеме правила): 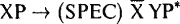
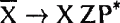
Просто подставьте существительное, глагол, прилагательное или предлог вместо X, Y и Z — и вы получите настоящие правила построения синтаксической группы, которые его расшифровывают. Эта рационализированная версия структуры составляющих называется «X? теория». Эта базовая модель синтаксической группы распространяется и дальше, на другие языки. В английском ведущее слово идет перед ролевыми исполнителями. Во многих языках расположение слов обратное, но это обратное расположение присутствует во всех синтаксических группах в данном языке. Например, в японском глагол идет после своего дополнения, а не перед ним. Японцы говорят: Кендзи суши съел, а не Кендзи съел суши. Предлог идет после своей именной группы: Кендзи к, а не к Кендзи (поэтому предлоги называются «послелогами»). Прилагательное идет после своего дополнения: Кендзи чем выше, а не выше, чем Кендзи. Смещаются даже слова, маркирующие вопросы, и говорится приблизительно так: ли Кендзи поел?, а не поел ли Кендзи? Японский и английский зеркально отражают друг друга. И такое же постоянство было обнаружено при рассмотрении других языков: если в каком-либо языке глагол идет перед дополнением, как в английском, то в этом языке будут предлоги; если глагол идет после дополнения, как в японском, то в таком языке будут послелоги. Это значительнейшее открытие. Оно означает, что сверхправила будут удовлетворять не только всем синтаксическим группам в английском языке, но и всем синтаксическим группам во всех языках, если внести одно изменение — устранить из каждого сверхправила упоминания о порядке слов слева — направо. Деревья становятся подвижными. Одно из правил будет звучать так: 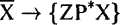
Чтобы это правило относилось непосредственно к английскому языку, нужно добавить информацию о том, что порядок слов внутри X-штрих — «с начальной позицией ведущего слова». Чтобы получить японский вариант, эта часть информации должна сообщать, что порядок «с конечной позицией ведущего слова». Аналогично, второе сверхправило (для синтаксических групп) можно подвергнуть дистилляции, так, чтобы испарился порядок слов слева-направо, а заданную на том или ином языке синтаксическую группу можно было восстановить, вернув в нее указание: «с начальной позицией X-штрих» или «с конечной позицией X-штрих». Та часть информации, варьируя которую, мы переходим от одного языка к другому, называется параметром. Фактически сверхправило меньше начинает становиться похоже на точную модель определенной синтаксической группы и больше — на основное направление или принцип того, как должны выглядеть синтаксические группы. Этот принцип можно использовать только в сочетании с определенными установками языка для параметра порядка слов. Эта общая концепция грамматики, впервые предложенная Хомским, называется «теорией принципов и параметров». Хомский предполагает, что сверхправила (принципы), в которых нет упоминания о порядке слов, являются универсальными и врожденными; когда дети овладевают тем или иным языком, им нет необходимости выучивать длинный список правил, потому что они родились со знанием сверхправил. Все, что им необходимо узнать, это является ли параметр порядка слов в их родном языке с начальной позицией ведущего слова, как в английском, или с конечной, как в японском. А узнать они это могут, просто заметив, стоит ли глагол перед дополнением или после него в любом предложении родительской речи. Если глагол стоит перед дополнением, как в предложении Eat your spinach! ‘Ешь свой шпинат!’, ребенок делает вывод, что в языке начальная позиция ведущего слова; если после дополнения, как в предложении Your spinach eat! ‘Свой шпинат ешь!’, ребенок делает вывод, что в языке конечная позиция ведущего слова. Таким образом, ребенку сразу становятся доступны огромные части грамматики, как если бы ребенок просто взял и переключил рубильник в одну из двух возможных позиций. Если эта теория усвоения языка верна, она поможет разгадать загадку того, как детская грамматика залпом превращается во взрослую за такой короткий промежуток времени. Дети не усваивают десятки сотен правил, они просто переключают несколько ментальных рубильников. * * *Принципы и параметры структуры непосредственно составляющих определяют лишь то, какие типы компонентов могут находиться в синтаксической группе и в каком порядке. Они не разбирают на части ту или иную конкретную синтаксическую группу. Если дать им волю, то они станут действовать, как одержимые, и будут виновниками всевозможных бед. Взгляните на следующие предложения, все из которых соответствуют принципам сверхправил. Помеченные звездочкой воспринимаются как неправильные:
Должно быть, виноват глагол. Некоторые глаголы, например, dine ‘ужинать’, отказываются появляться в компании именной группы прямого дополнения. Другие, например, devour ‘пожирать’, отказываются появляться без него. Это верно, даже несмотря на то, что dine и devour очень близки по значению — и тот и другой обозначают виды приема пищи. Вы можете смутно вспомнить уроки грамматики, где говорилось, что глаголы типа dine называются «непереходными», а глаголы типа devour — «переходными». Но глаголы выступают во многих ипостасях, не только в этих двух. Глагол put ‘поставить’ не успокоится, пока у него не будет прямого дополнения, выраженного именной группой (the car ‘машина’) и предложной группой (in the garage ‘в гараж’). Глагол allege ‘утверждать’ требует вложенного предложения (that Bill is a liar ‘что Билл — лжец’) и ничего другого. В таком случае, глагол является маленьким деспотом внутри синтаксической группы, диктуя, какие слоты, которые допустимы в рамках сверхправила, должны быть заполнены. Эти требования заданы в словарной статье к этому глаголу в ментальном словаре приблизительно так:
В каждой из этих словарных статей присутствует определение (в терминах мыслекода) некого события, за которым следуют его участники, у каждого из которых есть роль в этом событии. В словарной статье указывается, как каждый ролевой исполнитель может включаться в предложение — в качестве подлежащего, прямого дополнения, предложного дополнения, вложенного предложения и т.д. Чтобы предложение ощущалось как грамматически правильное, нужно удовлетворить запросы глагола. Melvin devoured ‘Мелвин пожирал’ — это плохо сказано, поскольку остается неудовлетворенной потребность глагола devour в заполнении роли «того, что съедается». Melvin dined the pizza ‘Мелвин ужинал пиццу’ — это плохо сказано, потому что глагол dine не требует слова pizza или любого другого дополнения. Поскольку именно глаголы определяют, как предложение сообщает информацию о том, кто что кому делает, невозможно рассортировать роли в предложении, не наведя справки о глаголе. Вот поэтому ваша учительница грамматики ошибалась, когда она говорила, что подлежащее в предложении — это «производитель действия». Подлежащее в предложении часто таковым является, но только если так велит глагол; глагол может также обязать его выполнять другие роли:
В действительности, у многих глаголов есть две различные словарные статьи, каждая из которых отводит ему различный набор ролей. Это может привести к сплошь и рядом встречающейся двусмысленности, как например, в старой шутке: Call me a taxi. OK, you’ re a taxi ‘Вызови мне такси (букв. также = назови меня такси). Будь по-твоему — ты такси’. В сериале «Харлем Глоубтроттерз» судья приказывает Медоуларку Лемону to shoot ‘бросить’ мяч. Лемон указывает пальцем на мяч и произносит: Bang! ‘Бах!’ (shoot означает как ‘бросить’, так и ‘выстрелить’). Комик Дик Грегори рассказывает о том, как он зашел в ресторанчик в штате Миссисипи во времена расовой сегрегации. Официантка заявила ему: We don’t serve colored people ‘Мы не подаем цветным людям’ (можно понять и как ‘Мы не подаем цветных людей’). «Прекрасно, — ответил тот, — я не ем цветных, мне бы кусок цыпленка». * * *И все-таки, как мы реально можем отличить фразу Man bites dog ‘Человек кусает собаку’ от Dog bites man ‘Собака кусает человека’. Словарная статья к слову bite ‘кусать’ говорит следующее: «Тот, кто кусает, является подлежащим; кусаемый объект — дополнением». Но как мы распознаем подлежащие и дополнения в дереве? Грамматика присваивает именным группам маленькие бирки, которые можно соотнести с ролями, отведенными глаголу в словарной статье. Эти бирки называются падежами. Во многих языках падежи выражены приставками и суффиксами у существительных. Например, в латыни существительные, обозначающие человека и собаку — homo и canis — изменяют свои окончания, в зависимости от того, кто кого кусает:
Юлий Цезарь знал, кто кого кусает, потому что существительное, обозначающее укушенного, имело на конце -em. Действительно, это позволяло Цезарю определить, кто укусил, и кто укушенный, даже если эти два слова менялись местами, что латынь допускает: Hominem canis mordet означает то же самое, что Canis hominem mordet, а Canem homo mordet означает то же самое, что Homo canem mordet. Благодаря показателям падежей глагольные словарные статьи могут снять с себя обязанность следить за тем, где именно их ролевые исполнители появятся в предложении; глаголу нужно только указать, что, скажем, производитель действия — это подлежащее; а на каком оно месте в предложении — на первом, третьем или четвертом — это дело остальных грамматических правил, понимание предложения от этого не меняется. И действительно, в языках с так называемым свободным порядком слов показатели падежей эксплуатируются в еще большей степени: и артикль, и прилагательное, и существительное в синтаксической группе снабжены определенным показателем падежа, что позволяет говорящему перетасовывать слова на протяжении всего предложения (например, поставить прилагательное в конец в целях эмфазы), зная, что слушатель сможет мысленно расставить их по местам. Этот процесс под названием «согласование», является вторым (помимо собственно структуры непосредственно составляющих) техническим решением проблемы, как перекодировать клубок взаимосвязанных мыслей в цепочки слов, следующих одно за другим. Века назад в английском, так же как и в латыни, существовали суффиксы, четко обозначавшие падеж. Но со временем они исчезли, и явно выраженный падеж остался только у личных местоимений: I, he, she, we, they ‘я’, ‘он’, ‘она’, ‘мы’, ‘они’ используются в роли подлежащего, my, his, her, our, their ‘мой’, ‘его’, ‘ее’, ‘наш’, ‘их’ — в роли обладателя, me, him, her, us, them ‘мне’, ‘ему’, ‘ей’, ‘нам’, ‘им’ используются во всех остальных ролях. (Различие между who/whom — ‘кто’ в именительном/в косвенных падежах — можно было бы добавить к этому списку, но оно изживает себя; в Соединенных Штатах whom постоянно используется только людьми, аккуратными на письме и претенциозными в речи.) Но что интересно: поскольку все мы знаем, что надо говорить He saw us ‘Он увидел нас’, а не He saw we ‘Он увидел мы’ синтаксическая нагрузка падежа в английском языке все еще жива и здорова. Хотя существительные внешне и не изменяются физически, какова бы ни была их роль, но все они негласно помечены падежами. Алиса поняла это, заметив мышь, плавающую рядом с ней в луже слез:
Носители английского языка присваивают именной группе показатель падежа в зависимости от того, к чему примыкает существительное (обычно — к глаголу или предлогу, но в случае с Алисой и мышью это был показатель архаичного вокатива O)[41] Эти падежные показатели используются, чтобы соотнести каждую именную группу с ролью, назначенной ей глаголом. Обязательность падежного показателя у именных групп объясняет то, почему некоторые предложения невозможны, даже если они и допускаются сверхправилами. Например, такой ролевой исполнитель, как прямое дополнение, должен стоять сразу после глагола, перед любым другим ролевым исполнителем. Мы говорим: Tell Mary that John is coming ‘Скажи Мэри, что придет Джон’, а не Tell that John is coming Mary ‘Скажи, что Джон придет, Мэри’. Мы говорим это потому, что существительное Мэри не может просто «болтаться» безо всякого показателя, но должно быть помечено показателем падежа — примыканием к глаголу. Интересно, что в то время как глаголы и предлоги могут маркировать примыкающие к ним существительные по падежу, существительные и прилагательные этого не могут: governor California букв. ‘губернатор Калифорния’ и afraid the wolf букв. ‘бояться волк’, хотя и понятны, грамматически они неправильны. Английский язык требует, чтобы не имеющий значения предлог of предшествовал существительному, как в governor of California и afraid of the wolf только для того, чтобы маркировать его по падежу. Глаголы и предлоги держат предложения, которые мы произносим, в ежовых рукавицах: синтаксические группы не могут появляться в глагольной группе там, где им хочется, они должны иметь «должностную инструкцию» и все время носить опознавательный знак. Таким образом мы не можем сказать что-то вроде: Last night I slept bad dreams a hangover snoring no pajamas sheets were wrinkled ‘Прошлой ночью я спал плохие сны, похмельный храп нет пижамы, простыни были смяты’, хотя слушающий и может догадаться, что здесь имелось бы в виду. В этом и состоит основное различие между естественными человеческими языками и, например, пиджин-языками или говорящими на жестовых языках шимпанзе, где любое слово может с большой вероятностью очутиться, где угодно. * * *А как насчет самой значительной синтаксической группы из всех — предложения? Если именная группа — это группа, построенная вокруг имени существительного, а глагольная группа — это группа, построенная вокруг глагола, то вокруг чего построено предложение? Критик Мэри Маккарти[42] однажды написала о своей сопернице — Лиллиан Хеллман[43]: «Каждое слово, которое она пишет, — это ложь, включая союз „и“ и артикль „the“». Это оскорбление основано на том, что предложение является минимальным отрезком информации, который может быть истинным или ложным; единичное слово не может являться ни тем, ни другим (таким образом, Маккарти утверждает, что лживость Хеллман распространяется дальше, чем можно было бы предположить). Отсюда следует, что предложение должно передавать значение, которое не просто складывается из значений его существительных и глаголов, но относится к комбинации слов целиком и превращает ее в суждение, которое может быть истинным или ложным. Возьмите, например, оптимистическое предложение: The Red Sox will win the World Series ‘«Ред Сокс» будут выигрывать первенство страны по бейсболу’. Слово will ‘будут’ относится не к одним только «Ред Сокс», и не к одному только первенству страны по бейсболу, и не к одной только победе: оно относится к единому понятию победы-«Ред-Сокс»-на-первенствах-страны-по-бейсболу. Само понятие лишено категории времени и потому лишено истинности. Оно может в равной степени относиться к минувшей славе или к предполагаемой будущей, даже к простому логическому предположению, лишенному всякой надежды на то, что оно когда-нибудь сбудется. Но слово will пришпиливает это понятие к временны?м координатам, а именно — к отрезку времени, следующему за тем моментом, когда было произнесено это предложение. Если я заявлю: The Red Sox will win the World Series ‘«Ред Сокс» будут выигрывать первенство страны по бейсболу’, — то я могу оказаться прав или неправ (к сожалению, скорее — второе). Слово will — это образец вспомогательного глагола, слова, которое выражает те составляющие значения, которые относятся к истинности суждения (как его воспринимает сам говорящий). Эти составляющие значения также включают отрицание (как в won’t и doesn’t ‘не будет’, ‘не был’), необходимость (must) и возможность (might и can). Вспомогательные глаголы обычно размещаются на периферии деревьев предложения, отражая тот факт, что они подтверждают некоторую информацию о предложении в целом. Вспомогательный глагол является вершиной предложения точно так же, как существительное является вершиной именной группы. Поскольку вспомогательный глагол также называется грамматическим показателем («inflection») — INFL, мы можем назвать предложение IP (группа грамматического показателя, или группа вспомогательного глагола). Позиция его подлежащего отводится подлежащему всего предложения, отражая тот факт, что предложение является утверждением, что некоторый предикат (VP) истинен по отношению к своему подлежащему. Вот как приблизительно выглядит предложение согласно современной версии теории Хомского: 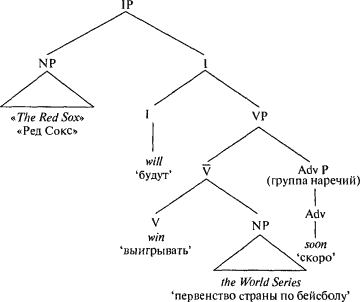 Вспомогательный глагол — это образец «функционального слова», слова отличного от существительных, глаголов и прилагательных — «полнозначных слов». Функциональные слова включают артикли (a, the, some) (неопределенный артикль, определенный артикль, мн. число неопределенного артикля), местоимения (he, she ‘он’, ‘она’), показатель принадлежности — ’s, лишенные самостоятельного смысла предлоги, например of, слова, которые вводят дополнения, например that и to и союзы, например and ‘и’ и or ‘или’. Функциональные слова — это частички грамматики в чистом виде, они очерчивают контуры бо?льших групп, в которые потом войдут NP, VP и АР, тем самым создавая строительные леса для предложения. И соответственно наш мозг обращается с функциональными словами не так, как с полнозначными. Люди постоянно пополняют язык новыми полнозначными словами (например, существительным fax ‘факс’ и глаголом to snarf ‘схватывать’) но функциональные слова образуют закрытый клуб, куда отказываются принимать новых членов. Поэтому и провалились все попытки ввести нейтральные по отношению к полу местоимения, такие как hesh или thon. Вспомните также о том, что у пациентов с нарушениями в «языковых» участках мозга больше проблем с функциональными словами, подобными or ‘или’ или be ‘быть’, чем с полнозначными, подобными oar ‘весло’ или bee ‘пчела’ — произношение которых аналогично словам or или be. В случаях, когда слова дорого стоят, как в телеграммах или газетных заголовках, авторы чаще всего исключают функциональные слова, надеясь, что читатель сможет их восстановить, ориентируясь на расположение смысловых слов. Но поскольку функциональные слова — самый надежный ключ к структуре предложения, телеграфный стиль иногда выходит боком. Однажды один журналист послал Кэри Гранту[44] следующую телеграмму: How old Cary Grant? ‘Сколько лет Кэри Гранту?’ или ‘Как старина Кэри Грант?’. Тот ответил: Old Cary Grant fine ‘Co стариной Кэри Грантом все в порядке’. Вот несколько газетных заголовков из коллекции под названием Squad Helps Dog Bite Victim (‘Отряд полиции помогает человеку, искусанному собакой’ или ‘Отряд полиции помогает собаке искусать человека’), которую собрали сотрудники газеты «Коламбия Джорнализм Ревью»:
В функциональных словах содержится многое из того, что делает один язык в плане грамматики не похожим на другой. Хотя функциональные слова есть во всех языках, свойства этих слов различаются таким образом, который может сильно повлиять на структуру предложений в языке. Мы уже видели один тому пример: четкие показатели падежа и согласования в латыни позволяют именным группам занимать в предложении разные места; отсутствие показателей падежа и согласования в английском заставляют именные группы оставаться на своем месте. В функциональных словах содержится грамматический образ и ощущение языка, как видно из следующих отрывков, которые используют функциональные слова языка и ни одного полнозначного слова:
(Перевод Д. Г. Орловской) Тот же эффект достигается в нижеприведенных отрывках, в которых функциональные слова взяты из одного языка, а полнозначные — из другого. Вот какое псевдонемецкое объявление висело во многих университетских компьютерных центрах англоговорящих стран:
В ответ на это компьютерные операторы в Германии с чистой совестью повесили на стену такой перевод на псевдоанглийский: * * * Каждый, кто ходит на вечерние коктейли, знает, что один из основных вкладов Хомского в науку — это теория «глубинных структур» вместе с «трансформациями», которые проецируют их на «поверхностные структуры». Когда Хомский ввел эти термины в атмосфере бихевиоризма ранних 60-х, реакция была сенсационная. Термин «глубинная структура» стал относиться ко всему, что было скрыто, основательно, универсально или значительно, и в очень скором времени стали говорить о глубинных структурах зрительного восприятия, рассказов, мифов, стихов, картин, музыкальных произведений и т.д. Сейчас, когда эта теория не находится в зените популярности, я должен раскрыть одну тайну: глубинная структура — это обычный технический инструмент грамматической теории. Это не значение предложения и не то, что универсально во всех человеческих языках. Хотя универсальная грамматика и абстрактная структура непосредственно составляющих, кажутся постоянными чертами грамматической теории, многие лингвисты (включая самого Хомского в его последних работах) считают, что можно обойтись без самой глубинной структуры как таковой. Чтобы устранить пафос, вызываемый словом deep ‘глубинный’, лингвисты теперь обычно говорят о ней, как о «d-структуре». Теория, в сущности, весьма проста. Вспомните о том, что для правильного построения предложения глагол должен получить все, что ему требуется: все роли, описанные в глагольной словарной статье должны появиться в отведенных им позициях. Но кажется, что во многих предложениях глагол не получает желаемого. Как вы помните, глаголу put ‘поставить’ необходимы подлежащее, дополнение и предложная группа; Не put the car ‘Он поставил машину’ и Не put in the garage ‘Он поставил в гараж’ звучат незаконченно. Но как нам тогда расценивать следующие совершенно правильные предложения:
В первом предложении глагол put, похоже, спокойно обходится без дополнения, что совсем не в его характере. И действительно, в данном случае он даже отвергает дополнение: The car was put the Toyota in the garage ‘Машина была поставлена Тойота в гараж’ звучит ужасно. Во втором предложении put также появляется на людях без дополнения. В третьем предложении отсутствует обязательная для него предложная группа. Означает ли это, что нам нужно ввести новые словарные статьи для глагола put, позволяя ему где-то появляться без дополнения, а где-то — без предложной группы? Разумеется, нет, иначе вернутся назад такие варианты, как He put the car ‘Он поставил машину’ и He put in the garage ‘Он поставил в гараж’. Конечно, в каком-то смысле недостающие синтаксические группы реально присутствуют в предложении, но только не там, где мы ожидаем их встретить. В первом предложении имеет место пассивная конструкция: NP — the car ‘машина’, играющая роль «того, что ставится», а им обычно бывает дополнение, вместо этого появляется в позиции подлежащего. Во втором предложении — специальном вопросе (wh-question, то есть вопросе, образованном со словами who ‘кто’, what ‘что’, where ‘где’, when ‘когда’ или why ‘почему’) роль «того, что ставится» выражена словом what ‘что’ и оно появляется в начале предложения. В третьем предложении роль «места» также появляется в начале вместо того, чтобы появиться после дополнения, где она обычно должно находиться. Простой способ разобраться со всей подобной ситуацией — это сказать, что у каждого предложения есть две структуры непосредственно составляющих. Структура, о которой мы до сих пор говорили, та, что определяется сверхправилами — это глубинная структура. Глубинная структура — это средство передачи взаимодействия ментального словаря и структуры непосредственно составляющих. В глубинной структуре все ролевые исполнители при глаголе put появляются на отведенных им местах. Затем трансформационная операция может «переместить» синтаксическую группу в незаполненный до того слой дерева. Там-то мы и находим эту синтаксическую группу в реально существующем предложении. Это новое дерево является поверхностной (surface) структурой (теперь она носит название s-структура, поскольку простое «поверхностное» представление никогда не могло завоевать должного уважения). Ниже приведены глубинная и поверхностная структуры пассивного предложения: 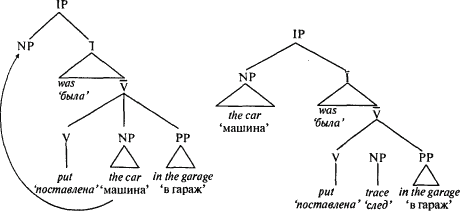 В глубинной структуре слева слово машина находится там, где оно требуется глаголу; в поверхностной структуре справа это слово там, где мы реально его слышим. В поверхностной структуре позиция, из которой была перемещена синтаксическая группа, содержит неслышимый символ, оставшийся в результате трансформации и называющийся «след». След служит напоминанием о той роли, которую играет перемещенная синтаксическая группа. След говорит нам, что о роли the car ‘машины’ при постановке в гараж мы можем узнать из словарной статьи к глаголу put ‘поставить’ и найти в ней слот «дополнение». Информация будет следующей: «поставленная вещь». Благодаря следу в поверхностной структуре есть информация, необходимая, чтобы восстановить значение предложения; изначальная глубинная структура, использованная только для правильного подбора слов из лексикона, не играет никакой роли. Зачем языкам понадобилось иметь по отдельности и глубинные и поверхностные структуры? Потому что для создания полноценного предложения требуется нечто большее, чем удовлетворить требования глагола (с этим справляются и глубинные структуры). Тому или иному понятию зачастую приходится играть две роли: одну — определяемую глаголом в глагольной группе, и, синхронно с этим, отдельную роль, не зависящую от глагола и определяемую другим уровнем дерева. Сравните предложение: Beavers build dams ‘Бобры строят плотины’ с его пассивным вариантом Dams are built by beavers ‘Плотины строятся бобрами’. На нижнем уровне — в глагольной группе (на уровне того, кто сделал что кому) — существительные играют одинаковую роль в обоих предложениях. Бобры занимаются строительством, а плотины строятся. Но на верхнем уровне (IP) — уровне отношений подлежащего и сказуемого (на уровне того, что утверждается о чем) — существительные играют разные роли. Предложение с активным залогом говорит о бобрах вообще и оказывается истинным, а предложение с пассивным залогом говорит о плотинах вообще и оказывается ложным (поскольку некоторые плотины, как например Плотина Гранд-Кули[47], построены не бобрами). Поверхностная структура, ставящая слово dams ‘плотины’ в позицию подлежащего в предложении, но одновременно соединяющая его со следом его изначальной позиции в глагольной группе, позволяет нам и съесть пирог, и одновременно иметь его. Кроме того, возможность перемещать синтаксические группы, в то же время сохраняя их роли, дает возможность порезвиться носителю языка с твердым порядком слов, такого, как английский. Например, группы, обычно глубоко спрятанные в дереве, могут выступать в предложении на первый план, где они соединяются с информацией, новой для слушателя. Например, если спортивный комментатор описывает, как движется по льду Невин Макварт, он может выразиться так: Markwart spears Gretzky!!! ‘Макварт настигает Грецки!!!’. Но если комментатор описывает положение Уэйна Грецки, он выражается так: Gretzky is speared by Markwart!!! ‘Грецки вот-вот будет настигнут Маквартом!!!’. Более того, поскольку пассивное причастие имеет возможность оставлять незаполненной в глубинной структуре роль производителя действия (как правило — подлежащего), это удобно, когда хочется умолчать об этой роли. Вспомните уклончивую уступку общественному мнению, сделанную Рональдом Рейганом: Mistakes were made ‘Были сделаны ошибки’. Соединение различных ролевых исполнителей с различными ролями в различных сценариях — это то, в чем грамматика преуспела. В таком специальном вопросе, как:
синтаксическая группа what ‘что’ живет двойной жизнью. На нижнем уровне структуры группы глагола (уровне кто-сделал-что-кому), позиция следа указывает на роль поставленной вещи. На верхнем уровне структуры предложения, (уровне что-утверждается-о чем), слово what ‘что’ указывает, что цель предложения — попросить слушателя указать тождество чего-то. Если бы ученому-логику потребовалось выразить смысл, стоящий за этим предложением, результат был бы следующим: «Для какого x Джон поставил x в гараж». Когда такие операции перемещения соединяются с другими компонентами синтаксиса, как в предложениях: She was told by Bob to be examined by a doctor букв. ‘Ей было велено Бобом быть осмотренной врачом’ или Who did he say that Barry tried to convince to leave? ‘Кому он сказал, что Барри пытался убедить их уехать?’ или Tex is fun for anyone to tease ‘Техасца всем нравится дразнить’, то эти компоненты так же замысловато и точно взаимодействуют друг с другом для передачи значения предложения, как детали лучших швейцарских часов. * * *Теперь, когда я разложил перед вами синтаксис на составные части, я надеюсь, что ваша реакция будет более благожелательной, чем у Элизы Дулитл или у Джека Кейда. На худой конец, я надеюсь, что вас впечатлило, каким «абсолютно совершенным и сложным органом» (по определению Дарвина) является синтаксис. Синтаксис сложно организован, но эта сложная организация имеет на то причину — наши мысли, несомненно, организованы еще сложнее, и в то же время мы ограничены речевым аппаратом, который позволяет произнести только одно слово в один момент времени. Наука уже начала проникать в сущность прекрасно организованного кода, благодаря которому наш мозг может передавать сложные мысли словами и их порядком. Процесс работы синтаксиса важен по другой причине. Грамматика явно опровергает эмпирическую доктрину, согласно которой в разуме содержится только то, что постигается через ощущения. «Следы», падежи, X-штрихи и все другие атрибуты синтаксиса не имеют ни цвета, ни запаха, ни вкуса, но они, или что-то похожее на них, должны быть частью нашей подсознательной ментальной жизни. Это не сюрприз для вдумчивого ученого-компьютерщика. Невозможно написать сколько-нибудь осмысленную программу, не определив, чему в точности будут соответствовать те или иные переменные и структуры информации при загрузке данных и при получении результата. Например, графическая программа, которой нужно поместить изображение треугольника внутрь круга, не будет запоминать, какие клавиши были нажаты пользователем, чтобы нарисовать эти фигуры, потому что они могли быть нарисованы в другом порядке или другим предметом, например, мышью или световым пером. Не будет она запоминать и список точек, которые нужно высветить на экране, чтобы воссоздать рисунок, потому что пользователь может впоследствии захотеть переместить круг, а треугольник оставить на месте, или сделать круг больше или меньше, а один длинный список точек не позволит программе узнать, какие точки принадлежат кругу, а какие — треугольнику. Вместо этого рисунок сохранится в памяти в некотором более абстрактном формате (например, в виде координат нескольких определяющих точек для каждой фигуры), в формате, который не отражает ни данные при загрузке, ни выходные данные, но может быть легко переведен в них и обратно, когда возникнет необходимость. Грамматика, являясь формой ментального программного обеспечения, должна была эволюционировать при таких же требованиях к ее организации. Хотя психологи под влиянием эмпирической доктрины часто предполагают, что грамматика отражает команды, данные органам речи, или мелодии звуков речи, или ментальный сценарий того, как обычно взаимодействуют люди и вещи, я думаю, что во всех этих предположениях упускается самое главное. Грамматика — это протокол передачи данных, который должен соединять слух, речевой аппарат и разум, три совершенно разных вида механизмов. Он не может быть приспособлен ни к одному из них, но должен иметь свою собственную абстрактную логику. Мысль о том, что организация человеческого разума предполагает использование абстрактных переменных и структур информации, была (и в некоторых кругах остается) шокирующим заявлением, потому что структуры как таковые не встречаются в повседневной речи, с которой сталкиваются дети. Начала грамматики должны быть заложены с рождения как часть механизма усвоения языка, позволяющего детям понимать звуки, издаваемые родителями. Синтаксис сыграл выдающуюся роль в истории психологии, являясь тем самым случаем, когда сложная организация мышления — не следствие обучения; возможность обучения есть следствие сложной организации мышления. Это-то и было настоящей новостью. Примечания:2 Стая жаворонков, букв. ‘восторг жаворонков’. Для сравнения: pride of lions — ‘львиный прайд’, букв. ‘гордость львов’. — Прим. перев. 3 Всем техническим терминам из лингвистики, биологии и когнитивной науки, что я использую в этой книге, дано определение в глоссарии на с. 438 и след. 4 HAL — взбунтовавшийся компьютер из романа Артура Кларка «Космическая одиссея 2001», C3 PO — робот из фильма «Звездные войны». — Прим. перев. 28 Аллен Вуди (наст. имя Стюарт Кенигсберг) (р. 1935) — известный американский актер, режиссер, сценарист. — Прим. ред. 29 Ham ‘ветчина’. — Прим. перев. 30 Sweetbreads — сладкое мясо, букв. «сладкие хлебцы» — зобная и поджелудочная железы и блюдо, приготовленное из них. — Прим. перев. 31 Пикшенери (pictionary) — игра, аналогичная шарадам, при которой игроки рисуют картинки, а не разыгрывают мимические сценки. — Прим. перев. 32 Имеется в виду высказывание художника Энди Уорхола: «В будущем каждый из нас будет знаменит в течении пятнадцати минут». — Прим. перев. 33 Инфинитивные конструкции типа to boldly go. — Прим. перев. 34 См. рус. пер.: Хомский Н. Синтаксические структуры // Новое в лингвистике. Вып. II. М.: ИЛ, 1962. С. 418. — Прим. ред. 35 Ecophagus — ‘пищевод’ (лат.). — Прим. перев. 36 Верхнюю и нижнюю часть картинки следует мысленно расположить слева и справа друг от друга. Я разделил картинку на две части, чтобы она помещалась на экран читалок. — Прим. автора fb2-документа Sclex’а. 37 «ТВ-гайд» — американский еженедельный журнал с программами телепередач на неделю, статьями по вопросам культуры и общественной жизни. Основан в 1953 г. — Прим. ред. 38 Килмер Альфред Джойс (1886–1918) — американский поэт, автор прославившего его стихотворения «Деревья» («Trees»). — Прим. ред. 39 Перевод Е. Бируковой, 1958 г. Акт IV, сцена 7. — Прим. перев. 40 Фунджи — низшие грибы. — Прим. ред. 41 В англ. тексте «Алисы»: «A mouse—of a mouse—to a mouse—a mouse—O mouse!» — Прим. ред. 42 Маккарти Мэри Тереза (1912–1989) — американская писательница, литературовед, театральный критик. — Прим. ред. 43 Хеллман Лиллиан (1905–1984) — американская писательница, драматург; получила золотую медаль Национального института и Американской академии искусств и литературы. — Прим. ред. 44 Грант Кэри (1904–1986) — американский актер, исполнитель ролей супергероев, символ целой эпохи американского кинематографа. — Прим. ред. 45 НБА — Национальная баскетбольная ассоциация (США). — Прим. ред. 46 Если это попытаться «перевести» на русский язык, то получится что-то вроде: АХТУНГ АЛЛУС, КТО СМОТРИРЕН! Этот дер комнат электронише оборудование наполненный ист. Дас компьютермашине пальцамихвататунг унд кнопканажиматунг нихт разреширен. Аллес ди «умельцен» ин дер расстояние стоярен мюсс унд спокойнише смотрирен. В другой случай ди нарушителен верден подзадколенкойударяйтен унд немедлинише выгоняйтен. — Прим. перев. 47 Плотина Гранд-Кули — одна из крупнейших в мире плотин; построена в 1934–1941 гг. на р. Колумбия в штате Вашингтон (США). — Прим. ред. |
|
|||
|
Главная | Контакты | Прислать материал | Добавить в избранное | Сообщить об ошибке |
||||
|
|
||||