|
||||
|
ТЕМА НОМЕРА: Археология СМИ в реальном времени Автор: Леонид Левкович-Маслюк Раскопки данных (data mining) — модная и пока еще редкая специализация на рынке инфотехнологий. Екатерина Солнцева, заместитель гендиректора фирмы «Медиалогия», помогла мне ознакомиться со всеми этапами работы системы раскопки текстов (text mining), созданной этой компанией. Сегодня наши любимые СМИ предстанут перед читателем в препарированном виде, в каком они кладутся на стол руководителям крупных корпораций и высшим государственным чинам. «Что», «как» и «зачем» текст-майнингаИзвлечение информации из средств массовой информации — дело тонкое, утомительное и крайне дорогое. Есть в этом какая-то нехорошая ирония — но факт остается фактом. До недавнего времени заниматься этим делом всерьез (во всяком случае, в России) могли позволить себе только самые мощные спецслужбы и самые важные из госорганов [Это всего лишь догадка. Откуда нам точно знать, что они там себе позволяют?] (что почти одно и то же). Причина проста: штат аналитиков — это всегда штучный, уникальный инструмент для решения штучных же задач (притом требующих гигантской и непрерывной черновой работы по сбору данных). Несмотря на то что прогресс компьютерных технологий уже много лет идет «муровскими» темпами, только в последние годы появились реальные возможности для демократизации в области массового мониторинга источников — весьма, впрочем, умеренной. Благодаря ей услуги по содержательному и представительному мониторингу СМИ доступны теперь и крупным корпорациям, и даже политическим партиям. Для чего им это нужно? Деннис Кахилл (Dennis Cahill), вице-президент компании Factiva (www.factiva.com), активно ведущей открытую компьютерную разработку информационных залежей СМИ, считает, что без текст-майнинга бизнес не сможет правильно учитывать значимые изменения в деловой, социальной, правовой сфере. Те самые «тренды» и «паттерны», которые желательно заметить вовремя и успеть среагировать. Что-то входит в моду, что-то выходит из моды. Над кем-то сгущаются тучи, над кем-то — рассеиваются. Обо всем этом можно узнать, тщательно анализируя общедоступные источники. Люди, занимающиеся фундаментальным анализом рынков — отслеживанием и изучением всех сообщений, имеющих отношение к поведению интересующих их акций или валют, — ведут такой анализ давным-давно, очень успешно и без всякого текст-майнинга. Но можно сказать и иначе — они ведут текст-майнинг собственными подручными средствами; почему бы не (про)дать им (и другим желающим) современный экскаватор? Главное — чтобы он не разнес на куски хрупкие черепки фактов, которые представляют основную ценность для инфоархеолога современности [Термин «история современности» стал популярным после того, как его использовал в названии своей книги Эрнст Генри, замечательный историк, публицист, а главное, разведчик. Текст-майнинг в этом смысле — археология современности, раскопки, ведущиеся одновременно с захоронением в бесчисленных файлах только что полученной информации.]. Кахилл приводит пример с ожирением (obesity) — точнее, со словом «ожирение», которое в конце 2003 года стало все чаще мелькать в печати и блогах. К середине 2004 года проблема obesity стала трендом, а гиганты фастфуда, которых обвиняли в провоцировании этого серьезного недуга, столкнулись с проблемами. А столкновения, утверждает Кахилл, можно было бы избежать, вовремя прибегнув к текст-майнингу. Достаточно было отследить графики упоминаний слова «ожирение» в связке с упоминанием крупнейших сетей быстрой еды. Сделав это, сети бы поняли, на какую из них в ближайшее время обрушится удар общественного мнения — и успели бы перестроиться в духе времени. Однако такие задачи — лишь первая ступень посвящения для профессионалов истинного текст-майнинга. Уровень серьезных систем сегодня позволяет компаниям браться за решение более деликатных вопросов. Управление репутацией. Можно отследить, какова тональность упоминаний данной компании в СМИ, как она меняется со временем, и попытаться понять — с чем связаны эти изменения. Конкурентный анализ. Из сообщений СМИ можно вытрясти более или менее правдоподобную картину расстановки сил в той или иной отрасли. Очень грубая модель такова — о ком больше и лучше говорят, тот и более успешен. Чтобы из этой грубой модели сделать сколько-нибудь рабочую, нужны очень серьезные усилия — ибо упоминания надо уметь классифицировать, рейтинговать по массе параметров, увязывать друг с другом и с целями исследования. Как ни странно, сегодня такой уровень уже достигнут — хотя полностью автоматизировать подобные вещи вряд ли возможно даже в принципе. Бизнес-разведка. Что тут есть от настоящей разведки — судить не берусь. Очевидно, однако, что — в сочетании с перечисленными выше запросами — разумная технология связывания ключевых упоминаний в цепочки может давать отличный материал для размышлений. Тем более что оригиналы статей и даже записи телепередач доступны мгновенно — но тут я уже перехожу к рассказу о подробностях, замеченных при личных наблюдениях за увлекательным процессом текстовых раскопок в офисе «Медиалогии». В текущую работу по мониторингу СМИ и поддержанию базы знаний здесь вовлечено около ста человек. Работа ведется круглосуточно, причем ночная смена, как правило, самая загруженная — в это время обрабатываются материалы изданий, которые придут к читателям утром. Обработка и анализ идут в несколько этапов. В сыром виде на вход системы непрерывно приходят по подписке огромное количество СМИ, а также собранные роботами интернет-ресурсы свободного доступа. Анализируются только российские СМИ (зарубежные, которых около трехсот, просто отправляются в постоянно обновляемый архив), в том числе транскрипты шести основных телеканалов. Самые большие базы отраслевых источников — по финансам и по ИТ. Все это сортируется, из полученных файлов извлекается текст и отправляется на дальнейшую обработку (начиная с этого момента, pdf’ы исходных материалов прессы, а также видеоматериалы привязаны к текстам ссылками). Обработка, необходимая для включения текстов в структурированную базу знаний, начинается с выделения объектов. Объект — это то, о чем можно спрашивать систему. Чаще всего — персона или компания. Иногда — страна (Украина, например). Выделение объектов в тексте проводит программа, она же анализирует уровень их упоминаемости. Если обнаруживается активно упоминаемый объект, которого нет в картотеке, он направляется аналитику, который составляет досье и добавляет объект в изучаемую базу. Объекты бывают трех типов — A, B, C. Сейчас в картотеке 25 тысяч объектов. Из них к типу B отнесены 6000, к А — 2000, остальные имеют тип С. Объекты типа С — это, как считают исследователи, практически всё, что вообще есть в публичной структуре информационного поля России. С учетом того, что крупнейших компаний у нас, согласно известным рейтингам, не более четырехсот, а «активно упоминаемых» и того меньше — звучит правдоподобно. Обработка объектов этого типа в текстах ограничивается их выделением. Каждое упоминание объекта типа В получает формальное описание — набор из пятнадцати параметров-атрибутов. Примеры атрибутов: роль этого объекта в сообщении; позитивно, негативно или нейтрально упомянут объект в текущем тексте; рубрика, в которой встретился данный текст (например, попадание в рубрику «Право» — вполне определенный сигнал); жанр; наличие прямой речи; наличие фотографии. Для объектов типа А определяются еще и связи — их 26 видов (скажем, «партнер», «конкурент», «руководитель», «контакт», «упоминает» и т. д.). Эти объекты — публичные политики, крупнейшие компании, политические партии и прочее, что постоянно на слуху и на виду. Обработка категорий А и В идет в основном вручную, хотя большая часть сопутствующей технической работы автоматизирована (доверить программе оценку контекста по принципу позитив/негатив нельзя, а локализацию прямой речи и сопутствующей фотографии — обычно можно). «Прямая речь в документе бывает очень важна, — говорит Катя Солнцева. — Если хочешь посмотреть, как развивается компания, берешь прямую речь руководителя и сравниваешь: что он обещал год назад и что обещает сегодня. Наличие фотографии полезно для исследований, в которых оценивается качество репутации». Обработанная таким образом информация заносится в базу знаний (этот драгоценный ресурс хранится на защищенных всеми возможными способами серверах Data Fort) и после этого начинает учитываться в ответах на запросы. В этих ответах рассчитывается также индекс информационного благоприятствования (ИИБ). Он учитывает массу факторов, связанных с упоминанием объекта: скажем, его роль в сообщении (уникален или перечислен в списке из десяти других), тональность оценки (позитив, негатив или нейтральность) и т. п. Формула расчета ИИБ сложна, как сложна и технология оценок, классификации подобных объектов с многочисленными атрибутами и — очень важно! — связями. Технология, используемая в системе, была разработана с участием известного математика, специалиста по классификации и статистическому анализу Юрия Благовещенского. Именно благодаря этой технологии — надо подчеркнуть, что она не сводится к алгоритмам, заложенным в систему; выбор параметров классификации, методика их присвоения объектам, лингвистический анализ — все это тоже в конечном счете элементы технологии текст-майнинга — появляется возможность очень быстро получать ответы на сложные запросы к базе. «Прочее», или В разведкуДля демонстрационного сеанса я попросил Катю поработать с давно знакомым «объектом», часто упоминаемым и на наших страницах — Российской академией наук. Первым шагом был простой запрос списка публикаций, упоминающих РАН, с начала этого года (рис. 1). Их оказалось около пяти тысяч — включая и телесюжеты, которые можно было немедленно просмотреть. После этого мы заказали график динамики публикаций за тот же период, с разбивкой по неделям (рис. 2). 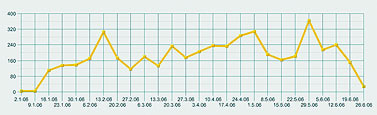 Полученная картинка выглядела не очень выразительно. Пики и спады были выражены нечетко, ясного представления о динамике общественного внимания к делам Академии они не давали. Вот тут мы и воспользовались одной из более сложных черт системы — запросили график числа публикаций, в которых Академия фигурировала в качестве главного объекта. Полученный по такому запросу рис. 3 был заметно более информативным. Как нетрудно заметить, он демонстрирует весьма четкие узкие пики, явно указывающие на серьезные события. Исследовать их все возможности не было, но щелкнув мышкой по самому позднему (он же самый высокий), мы взглянули на несколько появившихся на экране текстов, и сразу получили объяснение этому всплеску публикаций — в этот период прошли выборы новых академиков. С этим, как явствовало из тех же публикаций, была связана любопытная интрига с попыткой выдвижения в академики крупных бизнесменов и чиновников, чуть не приведшая к большому скандалу (Сергей Степашин, например, вежливо, но твердо отказался баллотироваться). 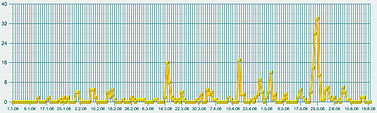 Следующий запрос — по каким рубрикам распределены упоминания Академии. И вот здесь нас поджидала маленькая сенсация. Полученную диаграмму вы видите на рис. 4. Оказывается, Академия наук чаще всего упоминается в наших СМИ в неведомых рубриках с собирательным названием «Прочее»! Там она фигурирует вдвое чаще, чем во второй по частоте категории — «Наука и образование», следующий по частоте контекст — «Власть», а процент упоминаний Академии как главного объекта статей по высоким технологиям находится уже где-то на уровне случайных колебаний. 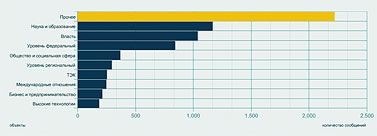 Катю Солнцеву результат удивил — никогда еще запрос ни по одному значимому объекту не давал такой статистики. Получается, что СМИ чаще всего пишут об Академии по каким-то нечетким, малозначительным поводам — и, что хуже всего, никак не связанным с ее основными миссиями. Разумеется, полученный результат надо еще уточнять и более детально анализировать. Но сигнал, тем не менее, весьма отчетливый: общество не очень понимает, чем занимается Академия, и далеко не всегда связывает ее деятельность с вопросами науки и образования. 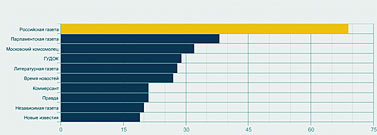 Следующий запрос — расклад по СМИ, упоминающим Академию (рис. 5). На первом месте — официоз (правительственная «Российская газета», «Парламентская газета»). Ведущие деловые издания пишут об Академии очень мало — скажем, «Ведомости» вообще не попали в список. Тест на позитив-негатив по тем же центральным газетам дал заметный перекос в сторону негатива (рис. 6) — но это вряд ли показательно, так как общее число таких сообщений очень мало — основная масса упоминаний оказалась просто нейтральной. 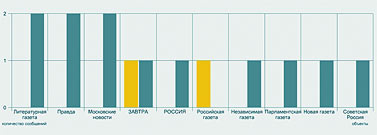 Ну а дальше мы попытались применить к собранной по академии статистике запросы как раз «разведывательного» характера. А именно, выбрав в качестве основного объекта Юрия Осипова [Вот пишу и думаю — а ведь и этот текст попадет в ту же самую базу, и тоже каким-то образом изменит статистику упоминаний и самой Академии, и ее президента…], Президента РАН, провели поиск по его «связям» с другими объектами — выстраивая при этом цепочки из двух промежуточных звеньев. Результат показан на рис. 7. 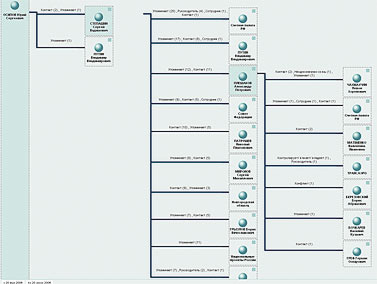 Очевидная интерпретация в данном случае невозможна — но характер получаемой информации ясен. Вряд ли более тщательный анализ именно этих цепочек раскроет какие-нибудь страшные тайны Академии наук. Не исключено, впрочем, что персонаж шпионских романов Ле Карре немедленно засел бы за просмотр всех документов, по которым выстроены отраженные на схеме связи. Мы же с вами можем просто обратить внимание на крайнюю узость круга людей, общение с которыми Президента Академии замечают СМИ. Если бы речь шла о рыночной конкуренции, можно было бы использовать и другие типы запросов по связям: поиск совместных упоминаний, скажем, конкурента и его клиентов в конфликтном контексте, объявления о проектах и результатах их реализации, оценку «уровня бесконфликтности», в том числе в связи с госорганами, и т. д. В случае Академии все это неинтересно и неприменимо — хотя бы потому, что конкурентов у РАН нет. Вот так сработал текст-майнинг на этом необычном (в «Медиалогии» не помнят, чтобы научные учреждения интересовались своим обликом в СМИ или динамикой репутации) запросе. Предупреждая саркастические письма прожженных наших читателей, сообщаю — да, я в курсе, что за скромные тысячи рублей можно купить у добрых людей базы данных банковских проводок, таможенных операций по любой компании страны и другие исчерпывающие, казалось бы, «разведданные». По этому поводу можно сделать два комментария. Во-первых, использование нелегальных источников информации дает, мягко говоря, не только преимущества. Во-вторых — персонализированных репутационных исследований нужной вам компании, сделанных по результатам вот такого интеллектуального мониторинга СМИ, у пиратов заведомо нет. Впрочем, обсуждать, что дает и чего не дает текст-майнинг «на самом деле» здесь бессмысленно. В России пара сотен компаний, общественных и госорганизаций использует эти технологии — это факт. Для чего это им нужно, насколько им это полезно — вопрос слишком тонкий, ибо одно из главных условий, которые должны быть обеспечены пользователям таких систем — секретность содержания их запросов. Краткое философское послесловиеО текст-майнинге приятнее всего рассуждать в абстрактных терминах и в будущем времени. Например, ясно, что здесь огромное поле для новых технологий поиска, взрывного роста которых мы все еще ждем. Ясно также, что развитие таких систем будет продолжаться, но потребует серьезных инвестиций (вышеупомянутая Factiva принадлежит сразу двум мощнейшим новостным агентствам, Reuters и Dow Jones; «Медиалогия» — проект нашего ИТ-гиганта IBS). Любопытно было бы и разобраться подробнее, что в таком контексте вкладывается (формально) в такие понятия как «факт», «достоверность». Но при знакомстве с используемой на практике системой текст-майнинга лично мне интереснее всего было убедиться, что никакие иллюзии насчет точности и качества «машинного» анализа текстов в систему не закладываются. Без сотни аналитиков ничего работать не будет — но без всей этой сложной программной лингвистическо-статистической кухни нужны были бы не сотни, а тысячи, а интервалы между запросами и ответами исчислялись бы не минутами, а неделями. Именно это, по-видимому, и обеспечивает сегодня существующую узкую рыночную нишу для текст-майнинга. Но она несомненно будет расти. Все больше говорят о потенциале «тегового» индексирования информации, и оно может радикально удешевить такие разработки. Впрочем, «персональной разведслужбы» пока не видно даже на горизонте. |
|
|||
|
Главная | Контакты | Прислать материал | Добавить в избранное | Сообщить об ошибке |
||||
|
|
||||